Announcing BCD Watch
Published 4 days past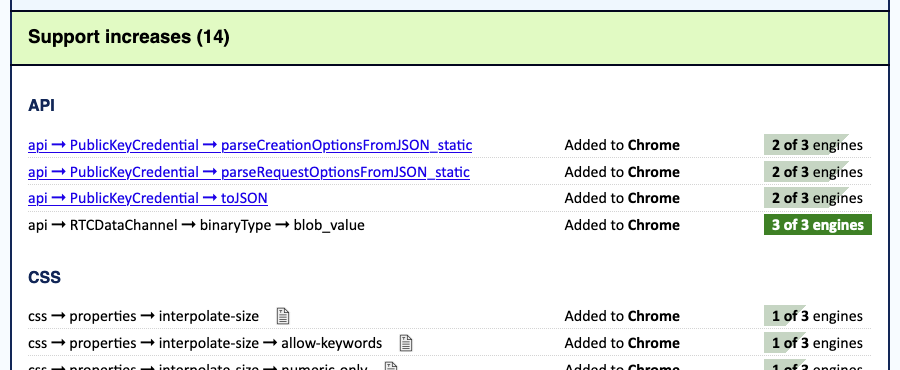
One of the things I think we all struggle with is keeping up to date with changes in web development. You might hear about a super cool new CSS feature or JavaScript API, but it’s never supported by all the browsers when you hear about it, right? So you think “I’ll have to make sure check in on that again later” and quickly forget about it. Then some time down the road you hear about it again, talked about like it’s been best practice for years.
To help address this, Brian Kardell and I have built a service called BCD Watch, with a nicely sleek design by Stephanie Stimac. It’s free for all to use thanks to the generous support of Igalia in terms of our time and hosting the service.
What BCD Watch does is, it grabs releases of the Browser Compatibility Data (BCD) repository that underpins the support tables on MDN and services like caniuse.com. It then analyzes what’s changed since the previous release.
Every Monday, BCD Watch produces two reports. The Weekly Changes Report lists all the changes to BCD that happened in the previous week — what’s been added, removed, or renamed in the whole of BCD. It also tells you which of the Big Three browsers newly support (or dropped support for) each listed feature, along with a progress bar showing how close the feature is to attaining Baseline status.
The Weekly Baselines Report is essentially a filter of the first report: instead of all the changes, it lists only changes to Baseline status, noting which features are newly Baseline. Some weeks, it will have nothing to report. Other weeks, it will list everything that’s reached Baseline’s “Newly Available” tier.
Both reports are available as standalone RSS, Atom, and JSON feeds, which are linked at the bottom of each report. So while you can drop in on the site every week to bask in the visual design if you want (and that’s fine!), you can also get a post or two in your feed reader every Monday that will get you up to date on what’s been happening in the world of web development.
If you want to look back at older reports, the home page has a details/summary collapsed list of weekly reports going back to the beginning of 2022, which we generated by downloading all the BCD releases back that far, and running the report script against them.
If you encounter any problems with BCD Watch or have suggestions for improvements, please feel free to open an issue in the repository, or submit suggested changes via pull request if you like. We do expect the service to evolve over time, perhaps adding a report for things that have hit Baseline Widely Available status (30 months after hitting all three engines) or reports that look at more than just the Big Three engines. Hard to say! Always in motion, the future is.
Whatever we may add, though, we’ll keep BCD Watch centered on the idea of keeping you better up to date on web dev changes, once a week, every week. We really hope this is useful and interesting for you! We’ve definitely appreciated having the weekly updates as we built and tested this, and we think a lot of you will, too.


.jpg){kind=link}