Fully managed in the cloud
Self-managed anywhere
Use the input above to search.
Here are some suggestions:
Join us for Datanova 2024, October 23-24th. We'll be discussing advancing analytics with Open Data Lakehouse innovations.

Companies building an open data lakehouse on Starburst

Data lakes promised a cost-effective, scalable storage solution but lacked critical features around data reliability, governance, and performance. And legacy lakes required data to be landed in their proprietary systems before you could extract value.
Enter the open data lakehouse.
The open data lakehouse is a cost-effective, performant, and future data architecture that is built on an open foundation:
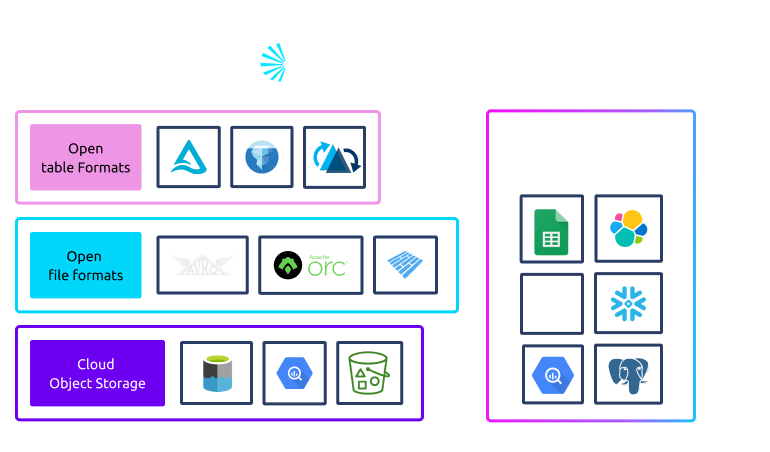
The open data lakehouse overcomes the limitations of legacy lakes, because it’s built with the understanding that center of gravity does not mean a single source of truth. It works with your other data sources in an open, scalable manner – creating a single, open system to access and govern the data in and around your lake.
Legacy Data Lake
Open Data Lakehouse
Access
Access
Limited to the data lake
Universal access to data in and around the lake
Table Formats
Table Formats
Limited to a single format (e.g. file formats in Hadoop)
Support for all modern formats Iceberg, Delta Lake, Hudi
Scalability
Scalability
Medium
High
Performance
Performance
Low
High
Cost
Cost
$ (can be expensive with proprietary vendors)
$
Use Cases
Use Cases
Raw data storage, ML
BI, SQL, ML, Real-Time Apps
Reliability
Reliability
Low quality, data swamp
High-quality, reliable data with ACID transactions
Governance
Governance
Poor governance because security needs to be applied to files
Fine-grained security and governance for row/columnar level for tables
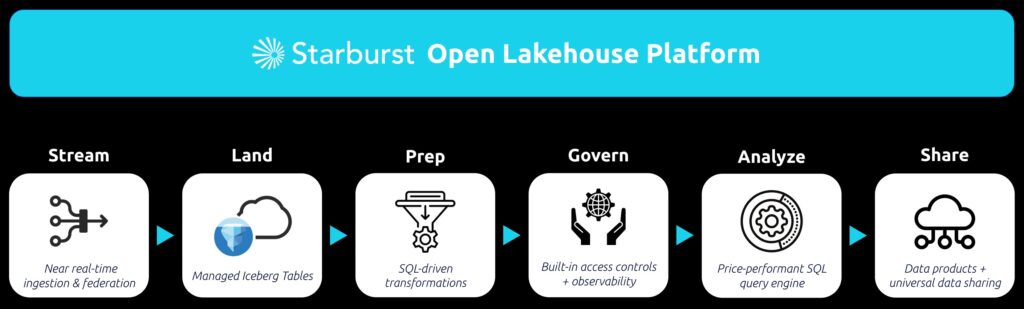
Starburst is the end-to-end platform for your open data lakehouse. It provides a single point of access for teams to discover, govern, analyze, and share data in and around your data lakehouse.
Hundreds of the most data-driven companies on the planet, including Grubhub, Verizon, and Lucid, chose Starburst to break down data silos and increase time-to-insight.
With a multitude of databases and data platforms, Genus’ data engineers were burdened by complex ETL pipelines that took weeks to run.
Time-to-insight was accelerated by 75% after turning to Starburst to query data directly from Genus’ data lakes (in Amazon S3 and ADLS).


Transitioning from a legacy data warehouse to an AWS cloud data lake proved challenging without a fast and reliable way to query its distributed data.
Having a powerful data lake analytics engine allows Zalando to accomplish its Customer 360 program, which increases wallet share and improves buyer recommendations.

Requests for data sets took hours, and sometimes days, to fulfill and required lots of movement between zones in the data lake.
Time-to-insight was reduced from days to seconds by using Starburst to explore near real-time data on and around Banco Inter's data lake.







© Starburst Data, Inc. Starburst and Starburst Data are registered trademarks of Starburst Data, Inc. All rights reserved. Presto®, the Presto logo, Delta Lake, and the Delta Lake logo are trademarks of LF Projects, LLC