1. Introduction
Feature selection is a critical process in network intrusion detection. Many previous works, such as [
1,
2], have shown that the accuracy of machine learning-based or deep learning-based methods is heavily affected by the feature space. The main challenge in designing efficient ML/DL-based intrusion detection is to choose a subset of relevant features without negatively affecting classification accuracy. Previous work [
3] has shown that different features contribute differently to detecting attack classes. Many efforts have concentrated on selecting important features for a monolithic classifier to detect and classify malicious attacks. For example, a single ML/DL-based classifier is proposed in [
4,
5]. In previous work [
6], a Random Forest model trained by 22 selected features of the CICIDS2017 [
7] dataset achieved an accuracy of 99.86%. Although the number of features is reduced, it is still not practical to monitor and log all selected features for detecting anomalous traffic and attacks, especially when coping with a large amount of traffic. Previous work [
2] suggests ten features from the same dataset, but it cannot identify some attacks with reasonable accuracy. Therefore, it is challenging to design a lightweight intrusion detection system that efficiently monitors fewer features to detect abnormal traffic and attacks.
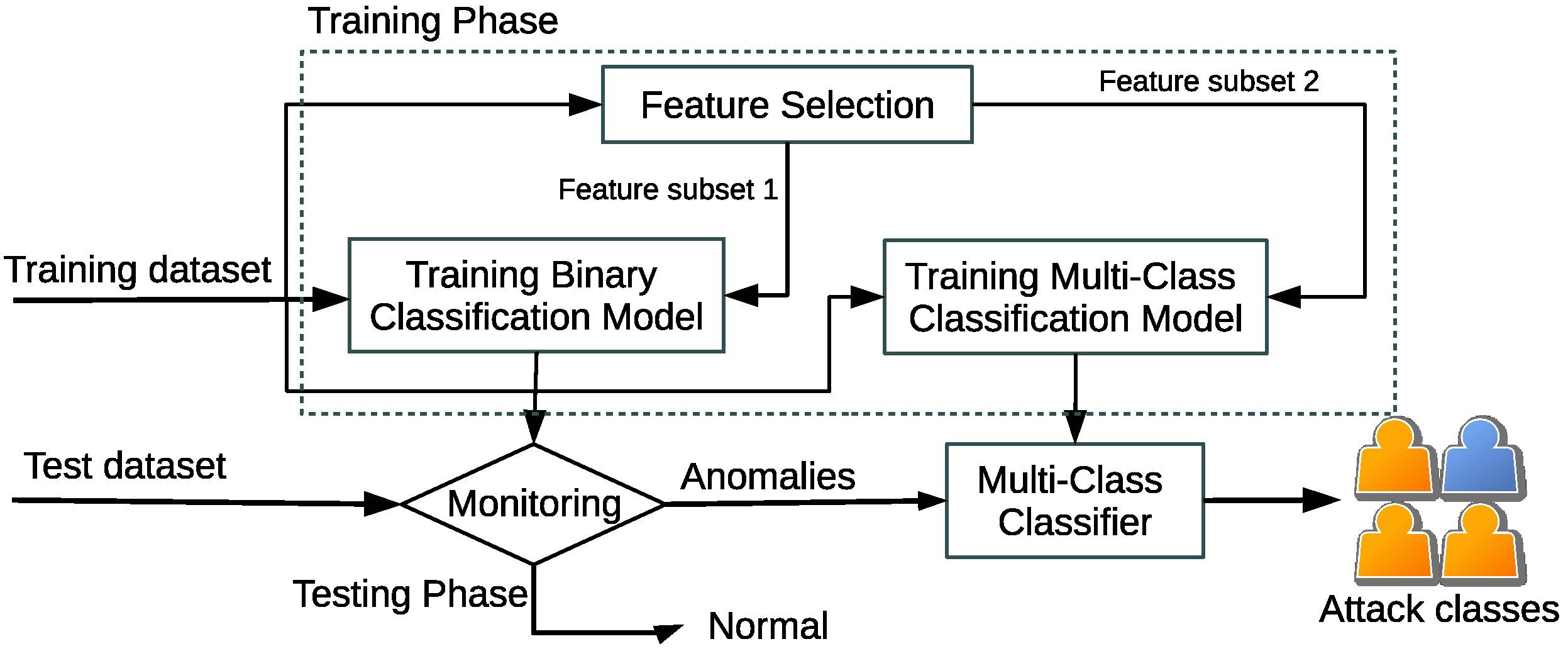
In this paper, we propose a two-stage MOnitoring and ClAssification (MOCA) system to detect and classify malicious network attacks. In the first phase of MOCA, a binary classifier monitors abnormal traffic. The monitor is trained by a small subset of features, which are carefully selected to distinguish anomalous traffic and attacks from normal traffic. The anomalous traffic captured by the monitor is forwarded for processing in a multi-class classifier at the second stage, where the attack classes are detected. With fewer features, MOCA makes it possible to develop a lightweight intrusion detection system to keep track of flow statistics. When flow exhibits behavior outside its normal range, it is monitored further at the second stage. Compared with related work, a two-step hybrid method that contains several binary classifiers and one aggregation module (KNN) is presented in [
8]. MOCA contains one single binary classifier and one multi-class classifier that identifies attack classes, meaning MOCA is more lightweight than the work presented in [
8].
The effectiveness of MOCA was evaluated by using the CICIDS2017 dataset [
7] and the CICDDOS2019 dataset [
9]. Our measurement results show that MOCA can effectively detect anomalous traffic and attacks with a few features. More specifically, using three to five features at the first stage, MOCA successfully differentiates anomalous traffic from normal traffic with an accuracy of almost 100%. Those features are directly derived from packet-level data or flow-level data, which makes MOCA suitable for monitoring real-time traffic by using sketching-based methods, such as count-min sketch [
10,
11].
Using 10 features overall, MOCA can identify attack classes in the CICIDS2017 dataset with an accuracy of 99.84% and attack classes in the CICDDOS2019 dataset with an accuracy of 93%, which significantly outperforms previous methods [
2,
6]. Using as few as eight features, MOCA has a much higher accuracy rate (i.e., 98%) on the CICIDS2017 dataset and 91% on the CICDDOS2019 dataset than when using only six features. Our measurement results demonstrate that connection features are highly useful for intrusion detection, and MOCA possesses the highest accuracy rate among the other methods designed for imbalanced attack classes.
Furthermore, MOCA mainly chooses
connection features to design the first stage classifier. Our measurement results show that benign traffic and DDoS attacks are the two classes benefiting from connection features. The CICIDS2017 dataset trained four decision tree-based binary classifiers to identify DDoS attacks. Each classifier is trained by one of the connection features, making it a lightweight classifier. Then, the pre-trained classifier is used to distinguish DDoS and Bot attacks from normal traffic in the ToN-IoT [
12], BoT-IoT [
12], CICIDS2018 [
7], and CICDDOS2019 datasets. Note that these datasets contain traditional IT and IoT traffic with different DDoS and Botnet attacks. We found that pre-trained classifiers can distinguish most DDoS and Botnet attacks from normal traffic. For example, the classifier can distinguish DDoS attacks from normal traffic in the CICDDOS2019 dataset with an accuracy of 96% and DDoS attacks in non-IoT and IoT traffic with an accuracy of 99.94%. To the best of our knowledge, MOCA is the first intrusion detection system to efficiently use a pre-trained model without retraining. Our measurements show that connection features [
13] effectively detect new DDoS and Bot attacks, especially when there are not enough training samples. They are also efficient features for minimizing the training and execution time of MOCA.
The rest of the paper is organized as follows. In
Section 3, connection features are introduced. In
Section 4, the proposed detection system is presented. The performance of our detection system is evaluated in
Section 5. Some related works are explored in
Section 2, and the paper concludes with a summary in
Section 6.
2. Related Works
Almost all previous work has focused on selecting important features without distinguishing connection features [
5,
14,
15,
16,
17]. For example, the results from previous works based on KDD-99 [
18,
19,
20], NSL-KDD [
21,
22], and UNSW-NB15 [
23] show that connection features typically are not listed as top-10 important features [
5,
16,
17]. An SVM-based attack detection system is proposed in [
24]. A modular deep neural network is proposed in [
25]. An analysis of the importance of CICIDS2017 features that used permutation importance to reduce the required features from the original 69 to 10 is reported in [
2]. The work presented in [
8] proposes a two-step hybrid method based on binary classification and kNN. It contains several binary classifiers and one aggregation module to detect attack classes effectively.
3. Connection Features
Researchers classify features into two particular classes: basic features and connection features. Basic features represent a single connection, while connection features are extracted from multiple connections. The preeminent objective of the two features is to identify two general types of attacks in network intrusion detection: attacks that require single connections, such as Web SQL Injection, and attacks that contain multiple connections, such as DDoS and Botnet attacks.
Distributed Denial of Service (DDoS) is a malicious attack in which numerous systems use malicious traffic to confuse a target server. In the CICDDoS2019 [
9] dataset, there are 13 DDoS attacks, such as DNS, MSSQL, SSDP, and UDPLag attacks. The following connection features are used to find the behavior of a client with a 100-connection window:
When there are multiple connections whose source IP address is the same as the current connection, the source count is extracted.
When there are multiple connections whose destination IP address is the same as the current connection, the dst count is extracted.
When there are multiple connections whose source port is the same as the current connection, the sport count is extracted.
When there are multiple connections whose destination port is the same as that of the current connection, the dport count is extracted.
When there are multiple connections whose destination and source IP addresses are the same as those of the current connection, the dst source count is extracted.
When there are multiple connections whose destination IP address and source port are the same as those of the current connection, the dst sport count is extracted.
When there are multiple connections whose source IP address and destination port are the same as those of the current connection, the source dport count is extracted.
The datasets used in this paper do not contain connection features. As a result, based on the original files, the seven connection features were derived for each sample as mentioned above.
4. MOCA Design
MOCA consists of a two-step approach: (1) monitor and detect anomalies, and (2) classify attacks.
Figure 1 depicts the framework of MOCA. Instead of training one ML/DL-based classifier, MOCA trains a binary classifier and a multi-class classifier. The binary classifier is to distinguish abnormal traffic from normal traffic. It is necessary to mention that all traffic is available prior to feature calculations. The multi-class classifier performs multi-class classification on the abnormal traffic to identify attack classes.
Two separated feature subsets are used for training classifiers. First, a small set of features is selected for a binary classifier to identify abnormal traffic. The second feature subset is selected for a multi-class classifier to identify attack classes. Various feature selection methods can determine the two feature subsets. The rest of this section focuses on the feature selection methods.
4.1. Feature Importance
This study measures feature importance using the following algorithms: information gain, correlation coefficients, and SHAP (SHapley Additive exPlanations) values. Consider
S a set of training-set samples with corresponding labels. Assuming there are
m classes, the training set contains
samples of class
, and
N is the total number of samples in the training set. The information needed to classify a given sample is calculated by the following equation:
Feature
F with values
can divide the training set into
v subsets
, where
is the subset with value
for feature
F. Furthermore, let
contain
samples of class
i. Entropy of feature
F is:
Information gain for
F can be calculated as:
It is noticeable that the information metric is a good measurement among different feature selection metrics to quantify the importance of features.
Correlation coefficients evaluate a subset of highly correlated features within an attack class but not correlated with each other. The correlation coefficient of a feature subset
F containing k features is given by [
5]:
where
is the mean feature-class correlation, and
is the average feature inter-correlation
The SHAP value [
26] of a feature is it contribution to the payout, it is weighted and summed over all possible feature combinations:
where
S is a subset of all features used in the model,
describes the vector of feature values of the instance to be explained, and
p is the number of features;
is the prediction of feature values in set
S that are marginalized over features not included in set
S.
4.2. Feature Selection
Feature selection techniques are divided into filter-based, wrapper-based, and embedded-based. In filter-based methods, someone selects features involving no ML algorithm. Filter methods are useful with respect to computing time. Wrapper-based methods employ a supervised learning algorithm to choose feature subsets. The two fundamental wrapper-based approaches adopted are Step Forward feature Selection (SFS) and Sequential Backward Selection (SBS). Embedded techniques incorporate optimal feature selection into an ML-based classifier.
In this paper, the integration of filter and embedded methods was necessary to select potential features, called pre-selected features, to improve the effectiveness of searching for the optimal feature subsets. Information gain and correlation coefficient were used as filter-based methods. Decision Tree, Random Forest, and XGBoost were used as embedded methods to calculate the importance of the pre-selected features. From each approach, the top-20 important features were derived. Then, a majority vote approach was taken to derive the pre-selected features.
After feature pre-selection, a feature-searching Algorithm 1 was proposed to select optimal feature subsets (
and
) for the two stages of MOCA. In this algorithm, pre-selected features are used to train a binary classifier. A SHAP TreeExplainer is used to derive important features of the model. Features with top-20 SHAP values are used as the starting features for the SBS method to find the minimum set of features. Each feature is deleted one at a time; classification accuracy is computed for all subsets with the remaining features, and the worst feature is discarded. To train the optimum model, cross-validation and hyper-parameter optimization played a role in bias reduction.
| Algorithm 1: Selecting features in MOCA. |
Input: pre-selected features , training dataset , two classifiers and , and the number of features Output: trained and with feature subsets Train a model m using and Explain m using shap.treeExplainer() Derive top-20 features according to SHAP values Train using and Train using and Search for the worst feature using and Update and if and then | return , , , and ; end Go to 5;
|
4.3. Binary and Multi-Class Classifiers
This paper uses Decision Tree, Random Forest, XGBoost, and multilayer perceptron (MLP) classifiers as binary and multi-class classifiers. These models are used to investigate the effect of selected features on the classification accuracy of classifiers. They minimize a feature subset that maximizes the binary classification performance while minimizing the number of selected features.
4.4. Performance Metrics
To effectively evaluate the performance of MOCA, four performance metrics, accuracy, precision, recall, and F1-score, were critical. More specifically, the following four metrics are considered for evaluating the performance of intrusion detection methods:
Accuracy: the sum of flows classified correctly with respect to the total number of flows. It is written by:
where TP is the number of true positives or simply the true positives, TN is the true negatives, FP is the false positives, and FN is the false negatives.
Precision: positive predictive value, equal to:
Recall: sensitivity or Detection Rate (DR), which is equal to:
F1-Score: the harmonic mean of the Precision and Recall. In other words, it is a statistical technique for examining the system’s accuracy by considering both precision and recall:
5. Measurement Results
In this section, the performance of MOCA in classifying attack classes was evaluated in the CICIDS2017 and CICDDOS2019 datasets. A total of 84 features in CICIDS2017 and 88 features in CICDDOS2019, including labels, were extracted based on real-world data (PCAPs). Flow ID, timestamp, IP, source, and destination port features were removed. In addition, 8 extra features in CICIDS2017 and 13 extra features in CICDDOS2019 were removed because they were all zeros. Based on the original features, connection features were derived for each sample. As a result, the datasets were left with 68 basic features in CICIDS2017 and 67 basic features in CICDDOS2019.
5.1. Binary Classification Accuracy
Table 1 shows the classification accuracy of an XGBoost-based classifier trained on different numbers of features. The table shows that using top-10 important features, including three connection features, can detect almost all abnormal samples in both datasets. Combining top-2 basic features (“Bwd Packet Length Min", “Subflow Fwd Bytes") with top-3 connection features (
,
,
) can distinguish abnormal traffic from normal traffic with an accuracy of 98.9% in the CICIDS2017 dataset and 99.98% in the CICDDOS2019 dataset. Using the three connection features detects 95% of abnormal cases in the CICIDS2017 dataset and 99.91% of attacks in the CICDDOS2019 dataset. MOCA has a higher accuracy rate for the CICDDOS2019 dataset. All attacks in the CICDDOS2019 dataset are DDoS attacks, which are sensitive to connection features. One aspect to highlight regarding the importance of connection features is that using top-5 basic features cannot detect all attacks.
5.2. Multi-Class Classification Accuracy
Decision Tree (DT), Random Forest (RF), and XGBoost are used as multi-class classifiers. This paper presents the measurement results from an XGBoost model because it has better performance than other models.
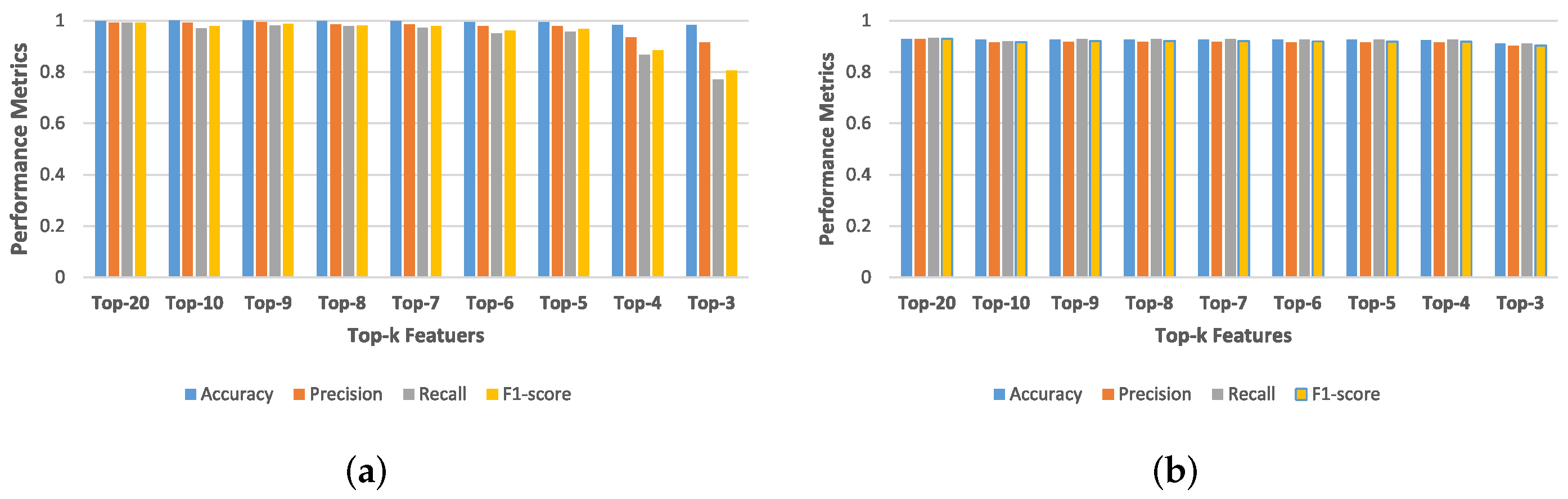
Figure 2 shows the performance of the classifier trained by top-k selected features. The top-k features are selected by Algorithm 1. The classifier trained using top-5 and top-3 features from both datasets had a very high detection rate.
The classification results for 14 classes in the CICIDS2017 dataset are shown in
Table 2. The last three entries in
Table 2 are the three attacks involving multiple connections. The results clearly show that MOCA can detect all three attacks, which is better than previous work [
2]. In [
2], a Random Forest model was trained by ten basic features. We found that MOCA can detect the majority of imbalanced web attacks. On the contrary, the model in [
2] could only detect a few attacks.
The results shows that MOCA improves performance over other methods, especially for imbalanced attack classes. Most previous works [
27] showed poor performance in detecting the web attacks in the CICIDS2017 dataset due to the imbalanced data based on the nature of different web attack behaviors. The SMOTE method [
28] has been applied to address the issue of imbalance by oversampling the imbalanced samples in the training dataset. MOCA presents very high detection accuracy in all three web attack classes without using the SMOTE method.
Table 3 shows the performance of MOCA in detecting 13 classes in the CICDDOS2019 dataset. Similarly, using three connection features to train the multi-class classifier can identify more attack classes than can a Random Forest model trained with all basic features.
5.3. Effectiveness of Pre-Trained Binary Classifier
To further investigate the benefit of using connection features, four Decision Tree-based binary classifiers were designed. Each classifier was trained by one feature (
,
,
, or
) and DDoS attacks from the CICIDS2017 dataset. Then, DDoS and Bot attacks were used from ToN-IoT [
29], BoT-IoT [
12], CICIDS2018 [
7], and CICDDOS2019 datasets to evaluate the pre-trained classifiers without retraining. Pre-trained decision trees distinguished DDoS and Botnet attacks from normal traffic. Note that these datasets contain traditional IT and IoT traffic (in BoT-IoT and ToN-IoT datasets) with different types of DDoS attacks. Each pre-trained binary classifier is a lightweight decision tree trained by one feature. The result is shown in
Table 4. The table shows that pre-trained classifiers can distinguish most DDoS and Botnet attacks from normal traffic. For example, in the CICDDOS2019 dataset, they had an accuracy of 96%. For the BoT-IoT dataset, a pre-trained classifier detected almost all DDoS attacks in non-IoT and IoT traffic with 99.94% accuracy.
We noticed that pre-trained classifiers contribute differently to detecting attack classes. For example, was used for the CICDDOS2019 dataset, and was used for the BoT-IoT dataset. The other two features, and , were used to classify DDoS attacks in CICIDS2018 and ToN-IoT datasets, respectively. The results show that connection features can be selected as the potential features for training a binary classifier instead of searching all features. The results also show that pre-trained binary classifiers can help detect new DDoS and Botnet attacks when training samples are unavailable. In addition, accuracy can be further improved by using the selected connection features and one or two basic features from the new dataset to train the classifier. Therefore, MOCA can minimize training time.
5.4. Comparing MOCA with Previous Works
Table 5 compares the results of MOCA with previous works. Because previous works used recall or decision rate, it was necessary to only compare their recall values with ours. From the table, the values for MOCA are higher than previous approaches. For example, SGM only achieved a slightly high recall value in Web Attack XSS. This observation implies that MOCA can efficiently address the effects of imbalanced malicious attacks on classification accuracy.





{kind=link}
{kind=link}