


Abstract
Predicting plasma evolution within a Tokamak reactor is crucial to realizing the goal of sustainable fusion. Capabilities in forecasting the spatio-temporal evolution of plasma rapidly and accurately allow us to quickly iterate over design and control strategies on current Tokamak devices and future reactors. Modelling plasma evolution using numerical solvers is often expensive, consuming many hours on supercomputers, and hence, we need alternative inexpensive surrogate models. We demonstrate accurate predictions of plasma evolution both in simulation and experimental domains using deep learning-based surrogate modelling tools, viz., Fourier neural operators (FNO). We show that FNO has a speedup of six orders of magnitude over traditional solvers in predicting the plasma dynamics simulated from magnetohydrodynamic models, while maintaining a high accuracy (Mean Squared Error in the normalised domain  ). Our modified version of the FNO is capable of solving multi-variable Partial Differential Equations, and can capture the dependence among the different variables in a single model. FNOs can also predict plasma evolution on real-world experimental data observed by the cameras positioned within the MAST Tokamak, i.e. cameras looking across the central solenoid and the divertor in the Tokamak. We show that FNOs are able to accurately forecast the evolution of plasma and have the potential to be deployed for real-time monitoring. We also illustrate their capability in forecasting the plasma shape, the locations of interactions of the plasma with the central solenoid and the divertor for the full (available) duration of the plasma shot within MAST. The FNO offers a viable alternative for surrogate modelling as it is quick to train and infer, and requires fewer data points, while being able to do zero-shot super-resolution and getting high-fidelity solutions.
). Our modified version of the FNO is capable of solving multi-variable Partial Differential Equations, and can capture the dependence among the different variables in a single model. FNOs can also predict plasma evolution on real-world experimental data observed by the cameras positioned within the MAST Tokamak, i.e. cameras looking across the central solenoid and the divertor in the Tokamak. We show that FNOs are able to accurately forecast the evolution of plasma and have the potential to be deployed for real-time monitoring. We also illustrate their capability in forecasting the plasma shape, the locations of interactions of the plasma with the central solenoid and the divertor for the full (available) duration of the plasma shot within MAST. The FNO offers a viable alternative for surrogate modelling as it is quick to train and infer, and requires fewer data points, while being able to do zero-shot super-resolution and getting high-fidelity solutions.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
Glossary
Convolutional Neural Network is a specialized type of artificial neural network designed for processing and analysing grid-like data, such as images, by using layers of learnable convolutional filters to automatically extract and learn hierarchical features from the input.
Hyperparameters are settings or configurations that are not learned from the data but are crucial for training and fine-tuning neural networks, influencing factors such as model architecture, learning rate, and batch size.
Long-short term memory are a variant of Recurrent Neural Networks modelling sequential data utilising various gates allowing the model to learn long-term forecasting. LSTM utilises several gates to learn, remember and forget embeddings that govern the long term sequential progression.
Markovian process or a Markov process, is a mathematical model for a random process in which the future state of the system depends only on its current state, and not on its past states, making it memory-less and characterised by a property called the Markov property.
Relative L2 loss is a way to compare two vectors or signals. It calculates the average squared difference between corresponding elements of the vectors X and Y, but it also takes into account the magnitude of the elements in Y. This normalization helps in comparing errors relative to the size of the target vector Y, making the comparison more meaningful.
U-Net is a type of convolutional neural network that gets its name from its U-shaped structure. Characterized by an encoder network for feature extraction and a symmetric decoder network for generating segmentation masks, setup with skip connections similar to a ResNet.
1. Introduction
Predicting the evolution of plasma dynamics is crucial to building sustainable fusion devices as it allows us to anticipate plasma behaviour and make real-time decisions over the input control parameters and alter the trajectory of plasma evolution. Such predictions also allow us to improve our understanding of the physics governing plasma interactions. In particular, Magnetohydrodynamic (MHD) modelling is of critical importance as it improves our understanding of the dynamical evolution of filaments that burst out of the plasma edge and reach the Tokamak's first wall, as shown in figure 1(a) [1]. These plasma filaments, called edge-localised modes (ELMs), are described by non-linear MHD, and can be modelled numerically, as shown in figure 1(b).

Figure 1. (a): Fast camera image of a MAST plasma during an Edge-Localised-Mode, where plasma filaments are ejected outwards due to MHD instabilities at the plasma edge. Reprinted from [19], with the permission of AIP Publishing. (b): The evolution of the filamentary structures during the multi-mode ELM simulation imaged with a synthetic fast camera diagnostic (time given in ms). Full-scale MHD simulations as shown in this figure demonstrate the structural similarities of MHD observed in simulations as well as within the experiment diagnostically captured using the visible camera. Reproduced courtesy of IAEA. Figure from [1]. © EURATOM 2020.
Download figure:
Standard image High-resolution imageIn fusion research, prediction of future plasma states is mostly undertaken using physics-based numerical modelling codes, such as BOUT++ [2], JOREK [3], JINTRAC [4] and SOLPS [5]. However, these simulations are computationally intensive, taking weeks for effective simulations to be run on high-performance computers [2]. They are also often complex in terms of software infrastructure and advanced solver library dependencies, making them difficult to deploy for rapid iterative modelling. With numerical solvers, we also encounter cases where the simulations do not converge due to model mismatch or other issues.
Machine learning (ML) offers an alternative data-driven path for obtaining quick, inexpensive approximations to numerical simulations, allowing for rapid iterative modelling [6]. Within plasma physics, ML-based surrogate models have been used to provide quick approximations for a range of solutions, from emulating turbulent transport [7–9], estimating the Tritium breeding ratio across Tokamak designs [10] to modelling edge plasma [11, 12].
Recently, a new class of data-driven ML models, known as neural operators (NO), has recently been at the forefront of surrogate modelling. Unlike other surrogate models, they directly learn the solution operator of the partial differential equation (PDE) in a discretization-convergent manner [13, 14]. Specifically, NO can predict at any resolution, unlike standard neural networks like convolutional neural networks. In other words, they learn the underlying continuum, making them suitable for learning solutions of PDEs. The output of NO converges to a unique function upon mesh refinement [15]. NO approaches are more data-efficient compared to other surrogate models [16], converge faster than traditional surrogate models, and can generalise better to various PDE settings. Considering these advantages, NO-based surrogate models have found application in emulating the plasma evolution across the domain of a Tokamak [17, 18].
Our Contributions
- We demonstrate trained Fourier neural operators (FNOs) that can be deployed as an emulator to perform real-time forecasting of the evolution of plasma as characterised by fast cameras on the MAST Tokamak. Our studies show that the FNO is capable of modelling the plasma across the full (available) shot duration ranging from the ramp-up to the L and H modes of operation.
- We devise a modified version of the FNO, capable of handling multiple variables that govern a family of PDEs. The multi-variable FNO allows us to pass field information of all the interested variables to the model, allowing for learning and encoding the mutual dependence of variables, which is essential for capturing the non-linear effects.
- We demonstrate the utility of the multi-variable FNO in (surrogate) modelling the evolution of plasma across a range of reduced MHD cases with increasing complexity. We conduct an extensive analysis of the various features of the FNO, performing ablation studies that evaluate the impact of various choices of the Hyperparameters across the model and training.
In this paper, we undertake an extensive study of the FNO due to its previously established superior cost-accuracy trade-off in both training and testing [16]. We use NO to model plasma within fusion devices, in both the simulation space and within the experimental domain. For the simulation domain, we consider the reduced MHD models to provide data to train the neural operator [3]. We study the solution of MHD equations in two spatial dimensions with multiple variables of interest. The simulations that we are interested in modelling represent the diffusion of a blob of plasma within a specified domain. The simulations presented here describe a simplified scenario to that of a full ELM simulation as given in figure 1(b). We iterate over increasingly complex cases of fluid models that govern the diffusion of a plasma blob in toroidal geometry.
In addition to numerical modelling, we demonstrate that FNOs can be trained to predict the evolution of experimental plasma as observed by high-speed cameras on the MAST spherical Tokamak. The ability to predict future plasma states based on camera imaging, as well as other plasma diagnostics, could allow us to design efficient control feedback loops for future fusion reactors. We build emulators of the fast camera that views across the central solenoid and at the divertor. We find these models to be capable of accurately predicting plasma evolution in real-time.
In this study, we use FNOs for both MHD simulations and experimental camera data due to the structural similarities of the plasma observed in both. The visual similarity of the MHD modelled in the simulation, and that captured by camera images in a fusion device is elucidated in figure 1(a). The fast camera images capture the MHD behaviour that is observed experimentally. Through this work, the FNO's utility is demonstrated in predicting both experimental and simulation dynamics. Although this study considers a simplified simulation setup, with filament cross-sections, in a 2D poloidal plane, instead of the full 3D representation, this paper lays the groundwork for future studies where surrogates could be trained from both simulation and experimental data simultaneously. However, in section 3.1.10, arguments of the challenges and potential methods of extending to a 3D modelling case are discussed.
A preliminary version of this work was presented at the AI for Science workshop during NeurIPS 2022, where we demonstrated, as a proof-of-concept, the utility of the FNO in modelling MHD scenarios [18]. In the previous work, we conducted a benchmark of the performance of the FNO against more traditional surrogate model architectures such as Convolutional-Long-short term memory [20] and U-Net [21]. Our findings established that the FNO takes significantly less time to train, requires fewer parameters, and outperforms the Convolutional-LSTM and the U-Net in emulating the diffusion of a blob of plasma described by reduced MHD [18].
The paper is organised as follows: section 2 produces a full description of the datasets and methods involved in the paper, ranging from the physics description of the simulations, the diagnostic setup of the experimental camera data and a formal definition of the FNO, its training configuration and the extension to the multi-variable FNO. Section 3 outlines the results of our experiments with using the FNO to learn and predict results from various simulation settings and camera configurations. The section comprises an in-depth analysis of the multi-variable FNO trained to solve different PDEs, exploring the impact of hyperparameters, training regime, and the training data. We also include a performance comparison of the individual FNO with that of the multi-variable FNO. Section 3 is concluded with the experimental results from the FNO trained to model the plasma evolution as captured by the visible camera looking at the central solenoid and the divertor. We summarise our key results in section 4 and conclude with a discussion on future extensions of the work.
2. Datasets and methods
2.1. MHD simulations of plasma Blobs
The FNO as a Neural-PDE solver is tested on three datasets of simplified MHD models, simulating the radial convection of plasma blobs in toroidal geometry, with coordinates system ( ). These three cases are designed with increasing complexity to test the utility, versatility, and capabilities of the FNO to emulate MHD models. The simplified MHD model is similar to the so-called Reduced-MHD model from [3], but with all magnetic fields and currents kept to zero, which is similar to the Euler system, and can be summarised by the continuity, momentum, and pressure equations:
). These three cases are designed with increasing complexity to test the utility, versatility, and capabilities of the FNO to emulate MHD models. The simplified MHD model is similar to the so-called Reduced-MHD model from [3], but with all magnetic fields and currents kept to zero, which is similar to the Euler system, and can be summarised by the continuity, momentum, and pressure equations:
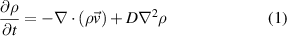
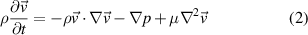
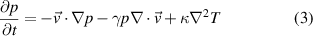
where ρ is the density, p the pressure, T the temperature, and  the velocity. D is the diffusion coefficient, µ the viscosity, and κ the thermal conductivity. The ratio of specific heats γ is taken to be that of a monatomic gas,
the velocity. D is the diffusion coefficient, µ the viscosity, and κ the thermal conductivity. The ratio of specific heats γ is taken to be that of a monatomic gas,  .
.
To obtain the Reduced-MHD model, the momentum equation (2) is projected in the poloidal plane using the operation  , while assuming the poloidal velocity takes the form
, while assuming the poloidal velocity takes the form  , where the electric potential Φ is equivalent to the velocity stream function in toroidal coordinates. This projection results in a system of three equations for the three variables ρ, Φ, T. A pseudo-variable is also used for the vorticity to reduce the level of derivatives in the system:
, where the electric potential Φ is equivalent to the velocity stream function in toroidal coordinates. This projection results in a system of three equations for the three variables ρ, Φ, T. A pseudo-variable is also used for the vorticity to reduce the level of derivatives in the system:  . We refer the reader to [3] and references therein for the full system of Reduced-MHD equations.
. We refer the reader to [3] and references therein for the full system of Reduced-MHD equations.
The simulations are all run in a square slab geometry of 1 m in width and height, centred at major radius R = 10 m. The runs are performed with toroidally axisymmetric plasma blobs initialised on top of a low background density and temperature. In the absence of a plasma current equilibrium to hold the density blobs in place, the pressure gradient term in the momentum equation generates a buoyancy effect, causing the blobs to move outwards. The simulations are run with the JOREK code, which is routinely used to model non-linear MHD instabilities in realistic geometries [3]. In this paper, we restrict ourselves to two simplified MHD models.
A further reduction of the model can be obtained by using constant temperature and removing equation (3) from the system, therefore evolving only ρ and Φ. With this isothermal model, the pressure gradient term in the momentum equation (2), which is proportional to ρ, acts as a buoyancy force on the blob, affecting its momentum  , which is also proportional to ρ. In other words, the velocity of the blob will be the same no matter what its density is. To have blobs moving at different speeds, the temperature inside the blob is needed: the higher the temperature, the faster the blob will move.
, which is also proportional to ρ. In other words, the velocity of the blob will be the same no matter what its density is. To have blobs moving at different speeds, the temperature inside the blob is needed: the higher the temperature, the faster the blob will move.
The values of the diffusive parameters are kept constant inside the entire domain, for all simulations, at D = 3.4 m2 s−1,  kg.m−1 s−1, and
kg.m−1 s−1, and  kg.m−1 s−1. The background density level is set to 1018 m−3, and the background temperature is set to 1 eV (for simulations that evolve temperature).
kg.m−1 s−1. The background density level is set to 1018 m−3, and the background temperature is set to 1 eV (for simulations that evolve temperature).
Three datasets are considered: with a single isothermal blob, with a single blob with non-uniform temperature, and with multiple blobs with non-uniform temperature. To create the datasets, the blob's initial conditions are varied. The sampled parameters are the number of blobs, their positions, their width, and their density and temperature amplitudes. This is summarised in table 1. For datasets with a single blob, the initial position is fixed at the centre of the domain,  . The smaller single-blob datasets are composed of 120 simulations (100 for training, 20 for testing), while the main dataset with multiple blobs contains 2000 simulations.
. The smaller single-blob datasets are composed of 120 simulations (100 for training, 20 for testing), while the main dataset with multiple blobs contains 2000 simulations.
Table 1. Domain range and sampling strategies across the initial condition parameters. The case numbers represent the simulation settings in which that parameter was sampled. 1—single isothermal blob, 2—single blob with non-uniform temperature, 3—multiple blobs with non-uniform temperature. ![$U\;[a, b]$](https://content.cld.iop.org/journals/0029-5515/64/5/056025/revision5/nfad313aieqn12.gif) refers to a uniform distribution bounded by a and b.
refers to a uniform distribution bounded by a and b.
| Parameter | Distribution | Nature | Case |
|---|---|---|---|
| Number of Blobs |
![$U\;[1, \;10]$](https://content.cld.iop.org/journals/0029-5515/64/5/056025/revision5/nfad313aieqn13.gif)
| Discrete | 3 |
| R—Position of Blobs |
![$U\;[9.4, \;10.4]$](https://content.cld.iop.org/journals/0029-5515/64/5/056025/revision5/nfad313aieqn14.gif) m m | Continuous | 3 |
| Z—Position of Blobs |
![$U\;[-0.4, \;0.4]$](https://content.cld.iop.org/journals/0029-5515/64/5/056025/revision5/nfad313aieqn15.gif) m m | Continuous | 3 |
| Width |
![$U\;[0.02,0.1]$](https://content.cld.iop.org/journals/0029-5515/64/5/056025/revision5/nfad313aieqn16.gif) m m | Continuous | 1,2,3 |
| Density Amplitude of Blobs |
![$U\;[1.0,\; 4.0]\times 10^{19}$](https://content.cld.iop.org/journals/0029-5515/64/5/056025/revision5/nfad313aieqn17.gif) m−3 m−3
| Continuous | 1,2,3 |
| Temperature Amplitude of Blobs |
![$U\;[12,\; 72]$](https://content.cld.iop.org/journals/0029-5515/64/5/056025/revision5/nfad313aieqn18.gif) eV eV | Continuous | 2,3 |
All cases are run with the same time-step size of  s, for 2000 time-steps in total. This is long enough for the blobs to evolve radially until they reach the wall (where Dirichlet boundary conditions are applied) and disappear through both convective mixing and diffusion. Since a small time-step size is necessary in the simulations to ensure numerical stability, the datasets are down-sampled to 200 slices for the training set. Likewise, the 2D poloidal grid resolution, which is
s, for 2000 time-steps in total. This is long enough for the blobs to evolve radially until they reach the wall (where Dirichlet boundary conditions are applied) and disappear through both convective mixing and diffusion. Since a small time-step size is necessary in the simulations to ensure numerical stability, the datasets are down-sampled to 200 slices for the training set. Likewise, the 2D poloidal grid resolution, which is  bi-cubic finite-elements in the simulations, is down-sampled to a regular grid of
bi-cubic finite-elements in the simulations, is down-sampled to a regular grid of  . The smaller single-blob datasets were run on the EOSC-hub cloud using 16 cores per run, and the larger dataset of 2000 multi-blob simulations was run on CINECA's Marconi HPC cluster using 48 cores per run. Each simulation requires approximately 350 core hours. Though each simulation is down-sampled to 200 time instances, we keep the focus of our emulator on short-term evolution up to the first 50 time steps.
. The smaller single-blob datasets were run on the EOSC-hub cloud using 16 cores per run, and the larger dataset of 2000 multi-blob simulations was run on CINECA's Marconi HPC cluster using 48 cores per run. Each simulation requires approximately 350 core hours. Though each simulation is down-sampled to 200 time instances, we keep the focus of our emulator on short-term evolution up to the first 50 time steps.
Simulations of blobs in slab geometry are related to turbulence and MHD instabilities at the plasma edge of a Tokamak by assuming that they represent a poloidal cross-section of a filament. As seen in figure 1, filament structures are aligned to the magnetic field, they are elongated in the toroidal direction, but have a nearly circular cross section in the poloidal plane. Such slab simulations represent the dynamic evolution of these filaments in the plane perpendicular to the magnetic field. Extensive modelling of blobs in slab geometry can be found in [22, 23] and references therein. Figure 2 shows an example of a numerical simulation of multiple blobs evolving for the first 500 steps (out of 2000), with the density, temperature, and vorticity. Filaments with higher temperatures can be seen to move at a faster velocity.

Figure 2. Evolution of multiple blobs inside a slab for the first 500 time-steps of the numerical simulation (the full run is 2000 steps), taken at intervals of 100 steps (about 15 µs). The top row shows the density, the middle row the temperature, and the bottom row the vorticity.
Download figure:
Standard image High-resolution image2.2. Fast-camera images on MAST Tokamak
MAST was equipped with fast camera imaging diagnostics at several points across the Tokamak for capturing images within the visible spectrum, capturing the plasma evolution in real-time 5 .
These Photron cameras
6
are essential diagnostics that contributed to fundamental understandings of key plasma phenomena in Tokamaks in recent years [24]. While most of the camera data has been used for qualitative analysis in the past, it can be exploited using more advanced methods to provide statistical insight into plasma turbulence [25], as well as global instabilities (disruptions) [26]. Within the scope of this work, we focus on two camera views. The first looks at the central solenoid and the plasma confined around it, extending to the walls and providing a holistic view of the plasma (rbb camera). The second camera configuration under study is that provid- ing the divertor-view, looking at the bottom of the Tokamak, where energy travels from the plasma to the exhaust region (rba camera). The views of the fast cameras on MAST in the absence of the plasma is visualised in figure 3. Figure 1 shows a view of the main plasma as seen by the camera, together with a synthetic rendering (right) of the camera, simulating the MHD physics. The cameras have a temporal resolution of 1.2 ms, with spatial resolution varying according to the desired calibration setup for each experiment. They are tuned to visible wavelength and, therefore, capture mostly the Balmer D light emitted mostly from the plasma edge. As seen in figure 1, the fast-visible cameras are able to capture complex dynamics of plasma filamentary eruptions at the plasma edge, the ELMs [24], hence being able to predict real-time evolution allows us to anticipate such plasma instabilities and other confinement related characteristics. Within the scope of this project, our focus relies on modelling the plasma confinement and its interactions with wall accurately, leaving the modelling of ELMs as the next potential research avenue.
light emitted mostly from the plasma edge. As seen in figure 1, the fast-visible cameras are able to capture complex dynamics of plasma filamentary eruptions at the plasma edge, the ELMs [24], hence being able to predict real-time evolution allows us to anticipate such plasma instabilities and other confinement related characteristics. Within the scope of this project, our focus relies on modelling the plasma confinement and its interactions with wall accurately, leaving the modelling of ELMs as the next potential research avenue.

Figure 3. Views of the fast cameras on MAST in the absence of plasma, obtained using illuminations on the 3D CAD model of MAST. Camera shown in figure (a), looks across the central solenoid, while the camera in figure (b) shows the view at the divertor.
Download figure:
Standard image High-resolution image2.3. FNO
The FNO [27] is a neural network-based operator learning method [13] that learns a mapping between two function spaces from a finite collection of observed input-output pairs. In the Neural Operator (NO) setting, we learn the mapping from the input function space A to the output function space U. The input values are given by the function  , defined on a bounded domain
, defined on a bounded domain  . Similarly, the output values are given by the function u, valued and defined on the bounded domain
. Similarly, the output values are given by the function u, valued and defined on the bounded domain  . The NO can be written as a parameterised representation of this operator across function spaces:
. The NO can be written as a parameterised representation of this operator across function spaces:

Gθ is a neural network configuration parameterised by θ and is composed of three elements:
- (i)Lifting: A fully local, point-wise operation that projects the input domain to a higher dimensional latent representation
 .
. - (ii)Iterative Kernel Integration: Expressed as a sum of a local, linear operator and a non-local integral kernel operator, that maps from, iterated from ν0 to νT
. The kernel integration is followed by a point-wise non-linearity.
- (iii)Projection: Similar to lifting, characterised by a fully local point-wise operation that maps the latent representation to that of the output domain.
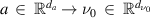
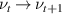
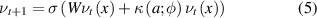
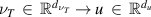
In equation (5), σ denotes the nonlinear activation, W represents the local, linear operator, and κ represents the chosen kernel which is parameterised by φ. x represents the input that is fed into that layer.
Conventionally, the lifting and projection within an NO are characterised by linear layers acting on the respective feature spaces. The kernel integration operator is characterised as the neural layer that evaluates a chosen kernel over the higher dimensional latent representation fed into it:
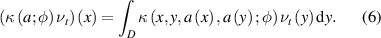
As demonstrated in [27], the FNO is devised by characterising the kernel integral operator as an operation within the Fourier space. Replacing κ with the Fourier integral operator  we obtain
we obtain
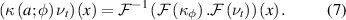
Here,  and
and  represent the Fourier and inverse Fourier transform, respectively. κ, the kernel is parameterised by learnable weights
represent the Fourier and inverse Fourier transform, respectively. κ, the kernel is parameterised by learnable weights  . Within the FNO, the kernel integrator reduces to the inverse Fourier transform of the inner product between the Fourier integral operator
. Within the FNO, the kernel integrator reduces to the inverse Fourier transform of the inner product between the Fourier integral operator  and the Fourier transform of the input to that Fourier layer
and the Fourier transform of the input to that Fourier layer  .
.
In practice, the iterative kernel integral transform with Fourier transform is characterised by two learnable weight matrices R and W as shown in figure 4. R learns the mapping behaviour within the Fourier space, while W learns the mapping required within the input Euclidean space. R characterises the non-local integral kernel operator, while W represents the local linear operators. The weight matrix R within the Fourier layer enables convolution within the Fourier space, allowing the network to be parameterised directly in it. The grid discretisation is also fed in at each layer to help the network learn the discretised Fourier representation of the data and undergoes point-wise linear transformations, characterised by C, its operation is similar to that of W. The output of a Fourier layer can be expressed as
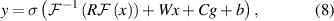
where x is the input to that layer, y the output, g the grid discretisation, b the bias and σ is the nonlinear activation function.

Figure 4. Modified architecture of a single Fourier Layer. FNO is constructed by stacking multiple Fourier layers on top of each other, sandwiched by a lifting and projection operation.
Download figure:
Standard image High-resolution imageEquation (8) resembles a single Fourier layer within the FNO. Multiple Fourier layers are stacked on top of each other to complete the iterative kernel integral operation. The stacked Fourier layers are sandwiched between the lifting and projection operations to complete the FNO architecture.
2.3.1. Comparison to convolutions.
The spectral convolutions characterised by κ in equation (7) have an analogous relationship to the convolutional operation. Convolution, being a product of functions across a certain range, is an integral transform. Expressed across an infinite range, it takes the mathematical form
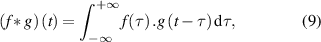
where f and g are functions over which the convolution operation is performed. By replacing the convolution operation with the Fourier transform in equation (9), we obtain
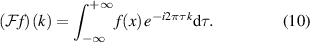
Comparing equations (9) and (10), it becomes evident how equation (7) is a special form of the convolutional operation, one that takes place in the Fourier space. In practice, both operations are applied across a discretisation, characterised by the data that is fed to the model, but since we decompose the data into Fourier modes within the FNO and apply learning across the decomposed components, we can learn continuous representations of the required mapping as opposed to learning discrete representations with conventional convolutions.
Named spectral convolutions in [27], allow for several advantages over a standard convolutional neural network, where filters are directly learned without a spectral transform. Firstly, by learning within the Fourier space, we allow the network to identify global features that are embedded within the data, highlighting the dominant modes in the process. By performing the Fourier decomposition over the data as it parses through the network, the weights are tuned to identify and learn the modes that possess a majority of the information, allowing the network to generalise better. Secondly, the spectral convolutions being in the function space allows for learning the mapping in a discretisation convergent manner, allowing for learning mesh-free solutions. Lastly, the Fourier transform in equation (10) is implemented using a Fast Fourier Transform (FFT) [28] which has a computational complexity of  , whereas the standard convolution operation without spectral transform has a complexity of
, whereas the standard convolution operation without spectral transform has a complexity of  , where k is the size of the kernel and n is the representation dimension. However, within the FNO, we only deal with a complexity of
, where k is the size of the kernel and n is the representation dimension. However, within the FNO, we only deal with a complexity of  ) since we truncate the Fourier modes up to a desired hyperparameter
) since we truncate the Fourier modes up to a desired hyperparameter  .
.
2.3.2. Training configuration.
For emulating the simulations, we use the FNO-2d configuration [27], where a 2-d FNO which only convolves in space, is deployed in an autoregressive manner [29]. The FNO takes in as its input the field values across a 2D grid for an initial set of time instances (T_in) along with the grid discretisation in both dimensions. Similar to spectral numerical solvers, the grid discretisation, fed in with the field data, provides better-structured information for discrete Fourier transform utilised within the FFT. The FNO takes the initial fields as the input and outputs a set of later time instances (step) of the field value across the same grid. The output of the FNO, coupled with the later time steps from the input, are then fed back in an autoregressive manner to estimate further field evolution in time, until the desired time instance (T_out) is reached. Within the autoregressive setting, we roll out the evolution of the fields up until the desired time step and then perform the backpropagation through time to enable learning of the time evolution of the PDE. For further information regarding the theory behind operator learning as ascribed by the FNO and its implementation in various case settings, we invite the reader to refer to the original work in [27]. Unlike the FNO 3D configuration, we only perform Fourier transformations across the spatial dimensions and do not include the temporal dimension. We have chosen the 2D configuration of the FNO as it is lighter, quicker, and gives us the flexibility in deciding the length of the temporal evolution.
For the case of the FNO for camera, instead of performing an autoregressive time roll out, we perform a fixed time window mapping, where the FNO takes in the camera information for fixed time steps (T_in) and outputs the next set of frames characterising the future plasma state (step). The next set of inputs is obtained by sliding the interested time window by one, as shown in figure 5.

Figure 5. Schematic representation of the two kinds of training configurations deployed within this study. For the simulations, we use the autoregressive configuration (left). We only use the initial set of field values to propagate towards the desired time step, where the intermediary model output is fed back into the model as inputs to further the time evolution. For the experimental data, we use a sequential time window-based configuration. Here, the model output is not factored back into the model, but we perform a fixed window mapping across time. As we go across the time duration of the data, the window is slid further by one-time instance (right). In the example above, we have T_in = 3, step = 1, T_out = 8, the time focus of each forward propagation of the model is given along the x-axis while the evolution across the full-time domain is given along the y-axis. Each cell block represents the 2D field value at a certain instance of time. The input and output sizes shown in this diagram are representative only and vary across each experiment.
Download figure:
Standard image High-resolution image2.3.3. Multi-variable FNO.
As depicted in equations (1)–(3), the physics model represents a highly correlated and interdependent system where density, temperature, and electric potential factor into the time evolution equations of each other. Taking this family of PDEs into account, it is vital to construct a surrogate model that is capable of emulating all variables together, allowing for information exchange within the model. The original FNO [27] was designed to model for a single variable and needed to be modified to handle multiple variables. The work done in [18] demonstrates the impact of the FNO on predicting MHD evolution but modelled each variable individually. Considering the simplicity of the reduced MHD case used in [18], it was permissible to model the variables independently. However, for the case under consideration, it was imperative that for physical consistency, we model the variables together. As we move into more complex MHD cases, we introduce more correlated variables such as density and temperature, which are both required to evolve together to fully grasp the propagation of the plasma blob.
To account for the multi-variable setting, we designed the FNO to take in the variables as a separate channel. Initial construction of the FNO would consider data in the format [batch size, temporal projection, spatial along x-axis, spatial along y-axis]. We modified that model to consider data in the format [batch size, variables, temporal projection, spatial along x-axis, spatial along y-axis]. This modification allows us to account for all the variables within a single model, which facilitates information exchange across them. By having the multiple variables of the physics model as a channel, we allow for the Fourier transform to be applied across the spatial domain for all variables of interest. The R matrix that allows for learning within the Fourier space in equation (8) is modified to account for the new variables, and the local, linear operator W acts across the variable and spatial domain. By providing the variables as a separate channel across the FNO, we introduce the possibility of performing the operations of lifting and projection defined in section 2.3 not just across the temporal features but across the fields as well. Thus, within this configuration of a multi-variable FNO, the feature space becomes two-fold, accounting for the time as well as the variables. We also modify the FNO with skip connections to reduce the information loss as the data progresses through the network [30]. The network architecture is outlined under Appendix
3. Results
Prior to elaborating on the finer details of the results from our experiments, we provide an overview of the performance obtained by the FNO surrogates across all the interested modelling tasks in table 2. Across our range of experiments, emulating the plasma, we find that the FNO achieves considerable accuracy (Mean Squared Error (MSE) in the normalised domain  ). Despite being heavily parameterised, the FFT within the network helps the FNO achieve quick training and execution times for surrogate models [18]. The Fourier features extracted help provide the model with implicit bias found in the data, allowing it to converge quicker on the spatial evolution of the plasma. By transforming the data to the Fourier space, we allow the network to easily extract the dominant features found in the data as they would be highlighted across the various Fourier modes. As mentioned in section 1, we focus our experiments solely on the FNO as the chosen surrogate. For a detailed benchmark of MHD emulators across various models, we refer to our prior work [18].
). Despite being heavily parameterised, the FFT within the network helps the FNO achieve quick training and execution times for surrogate models [18]. The Fourier features extracted help provide the model with implicit bias found in the data, allowing it to converge quicker on the spatial evolution of the plasma. By transforming the data to the Fourier space, we allow the network to easily extract the dominant features found in the data as they would be highlighted across the various Fourier modes. As mentioned in section 1, we focus our experiments solely on the FNO as the chosen surrogate. For a detailed benchmark of MHD emulators across various models, we refer to our prior work [18].
Table 2. Overview of the performance obtained by various FNO-based surrogate models built to emulate the plasma evolution in both simulations and experiments. The case represents the various simulation settings of JOREK or the camera diagnostic on MAST, for which we are training an emulator. The variables mention the number of variables from the PDE/diagnostic that we model together. Parameters refer to the number of parameters in the trained FNO, and MSE represents the mean squared error in the normalised domain. The Training Size represented the simulation/experimental input-output pairs. All models are trained on a single Nvidia A100 chip.
| Case | Variables | Parameters | Train Time (m) | Training Size | MSE |
|---|---|---|---|---|---|
| Single blob—isothermal | 2 | 6321 000 | 48 | 100 |
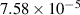
|
| Single blob—non-uniform temperature | 3 | 9467 000 | 97 | 160 |
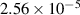
|
| Multiple blobs—non-uniform temperature | 3 | 9467 000 | 682 | 1500 |
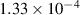
|
| Camera—Solenoid (rbb) | 1 | 201 900 | 1568 | 7661 |
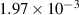
|
| Camera—Divertor (rba) | 1 | 201 900 | 935 | 5851 |
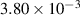
|
3.1. Multi-variable FNO over MHD Simulations
We design and train multi-variable FNOs to model the three MHD cases under study: Single isothermal blob, single blob in a non-uniform temperature field, and multiple blobs in a non-uniform temperature field, as described in section 2.1. Each multi-variable FNO is constructed as described in section 2.3.3 and trained using the autoregressive framework outlined in section 2.3.2.
For each multi-variable FNO, we chose an input feed of 10 time steps of the field information (T_in = 10), and an output size of 5 (step = 5). Each time step within the FNO corresponds to 1.5 µs of simulation time. Each FNO was autoregressively rolled out until the 50th time instance, allowing the neural operator to learn the time evolution of the function till then (T_out = 50). Each Fourier layer within the multi-variable FNO has 16 modes and a temporal channel width of 32 (unless mentioned otherwise). The temporal channel width in the FNO is akin to the channel width in a Convolutional Neural Network, where the temporal data is scaled in the FNO channels instead of the RGB color space in the CNN channels [31]. The channel variable width was maintained at the number of variables that the FNO learned. The grid discretisation associated with the field data is added to the training data within each model's forward call as an addition to the temporal channel, providing further field information to the model. We utilise the discretisation used within JOREK to generate the training data as the grid features within the FNO. We deploy a two-fold normalisation strategy considering the nature of the dataset. The physical field information represented within the MHD cases is in different scales, with densities ranging from 0 to 1020 m−3 and temperature ranging up to 100 eV. Since we consider the gradual diffusion of an in-homogeneous density blob(s), the data distribution within the spatial domain is severely imbalanced. Taking these aspects of the training data into consideration, initially the field values are scaled down by a factor, indicative of the range of operation found within the simulation itself. The physics scaling would divide the data by the order of magnitude around which the plasma operates for each variable. We perform this by scaling the field value with the order of magnitude of its maximum found in the training data. This is followed up by a linear range scaling, allowing the field values to lie between −1 and 1. The normalisation pipeline is implemented separately for each of the variables that the multi-variable FNO accounts for. Each model is trained for up to 500 epochs using the Adam optimiser [32] with a step-decaying learning rate. The learning rate is initially set to 0.005 and scheduled to decrease by half after every 100 epochs.The input, output dimensions and the model architecture used for each case is given in
The loss function is expressed as an equally weighted linear combination of two elements: the reconstruction error and the difference error, expressed as

Download figure:
Standard image High-resolution imagewhere  represents the FNO output at the time step t, yt
represents the labelled (actual) data at time frame t, step represents the step size of the FNO output, T represents the full length of the autoregressive time roll-out and N, the batch size or the number of simulations we are learning at a time over which we sum over.
represents the FNO output at the time step t, yt
represents the labelled (actual) data at time frame t, step represents the step size of the FNO output, T represents the full length of the autoregressive time roll-out and N, the batch size or the number of simulations we are learning at a time over which we sum over.
The reconstruction error helps the FNO to learn to minimise the prediction error for a particular instance in time, whereas the difference error helps learn the time evolution of the plasma better as it minimises the temporal differences that arise in the autoregressive roll-out of the FNO. The loss curves associated with each experiment can be found in figure 6.

Figure 6. Learning curves associated with training the multi-variable FNO across the various the various Reduced MHD Cases. Isothermal blob refers to the single blob diffusion under uniform temperature, Anisothermal blob refers to the single blob under a non-uniform temperature, and Anisothermal multiple Blobs extend that to the case with several density blobs under a non-uniform temperature distribution.
Download figure:
Standard image High-resolution imageThe focus of this research relies on the short-term evolution of up to 50 time steps from a total of 200 time steps, seeing how well the multi-variable FNO can model the evolution of all the physical variables in an integrated manner. We restrict ourselves to the short-term due to the errors arising from the autoregressive time rollouts, which are further explored in sections 3.1.4-3.1.6. To see the performance of the FNO deployed in an autoregressive setting for the full time range of the simulation, see appendix
3.1.1. Single blob—isothermal.
For the first case, that of a single blob in an isothermal setting (hereby referred to as an isothermal blob), the multi-variable FNO models the evolution of the two variables: density ρ and electric potential Φ. Considering the simple structure of the physics, the FNO performs well in (surrogate) modelling the evolution of both the variables arriving at an MSE (in the normalised domain) of  in 48 min on a single Nvidia A100 chip. The multi-variable FNO is capable of emulating the evolution of the plasma up to the 50th time step in 0.025 s, offering a speedup of 6 orders of magnitude as shown in figure 7. Further plots showing the contrast of the FNO output with that of JOREK by way of discrepancy plots can be found under appendix
in 48 min on a single Nvidia A100 chip. The multi-variable FNO is capable of emulating the evolution of the plasma up to the 50th time step in 0.025 s, offering a speedup of 6 orders of magnitude as shown in figure 7. Further plots showing the contrast of the FNO output with that of JOREK by way of discrepancy plots can be found under appendix

Figure 7. Isothermal Blob: Temporal evolution of (a) density and (b) electric potential of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution image3.1.2. Single blob with non-uniform temperature.
Moving up in complexity, in the case of a single density and temperature blob, the FNO is adapted to model density, electric potential, and temperature, three highly correlated variables as described in section 2.1. Even considering the additional physics, the multi-variable FNO demonstrates the ability to learn the global features of blob diffusion. It characterises the movements of the blob, its interaction with the walls, and its eventual dissipation. We notice that with the added field variables, the FNO performs well in predicting the evolution within the initial timesteps, but loses rigour of structure as we roll further out in time. Despite the challenge of preserving minor features further into time, the multi-variable FNO achieves an MSE (in the normalised domain) of  as shown in figure 8. The model trains in 1 h 37 min on a single Nvidia A100 chip. The multi-variable FNO is capable of (surrogate) modelling the evolution of the plasma up to the 50th time step in 0.03 seconds. Further plots showing the con- trast of the FNO output with that of JOREK by way of discrep-ancy plots can be found under appendix
as shown in figure 8. The model trains in 1 h 37 min on a single Nvidia A100 chip. The multi-variable FNO is capable of (surrogate) modelling the evolution of the plasma up to the 50th time step in 0.03 seconds. Further plots showing the con- trast of the FNO output with that of JOREK by way of discrep-ancy plots can be found under appendix

Figure 8. Single Blob : Temporal evolution of (a) density and (b) electric potential and (c) temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution image3.1.3. Multi-Blobs with Non-uniform temperature.
Figure 9 shows the capability of our newly designed multi-variable FNO in emulating the evolution of density, electric potential, and temperature for the case with multiple density and temperature blobs. This presents a more challenging case to model as the distribution of the training data is wide due to it being generated from a much larger parameter space as described in table 1. With a training dataset of 1500 simulations, the model trains in 11 h and 22 min on a single Nvidia A100 chip and achieves MSE(in the normalised domain)  , capturing the larger, more global, features associated with the evolution of plasma characteristics. However, due to the truncated nature of the implementation of the linear operator over the Fourier Transform, the modelling gets limited to the more dominant modes, smoothing out the less dominant, minor, finer features. The multi-variable FNO is capable of (surrogate) modelling the evolution of the plasma up to the 50th time step in 0.03 s. Further plots showing the contrast of the FNO output with that of JOREK by way of discrepancy plots can be found under appendix
, capturing the larger, more global, features associated with the evolution of plasma characteristics. However, due to the truncated nature of the implementation of the linear operator over the Fourier Transform, the modelling gets limited to the more dominant modes, smoothing out the less dominant, minor, finer features. The multi-variable FNO is capable of (surrogate) modelling the evolution of the plasma up to the 50th time step in 0.03 s. Further plots showing the contrast of the FNO output with that of JOREK by way of discrepancy plots can be found under appendix

Figure 9. Multiple Blobs with non-uniform temperature: Temporal evolution of (a) density (b) electric potential and (c) temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution imageThe FNO deployed in the autoregressive manner is well equipped to model the evolution of the plasma for short time roll-outs, but as we extend the prediction further in the temporal domain, it moves further away from the ground truth. This arises mainly due to the training regime which we deploy the FNO. Being deployed in an autoregressive structure, the prediction errors accumulate over longer time roll-outs. This is illustrated in figure 10. Though we demonstrate the results obtained with 1500 simulation data points, for the rest of the ablation studies (except for sections 3.1.7 and 3.1.8) demonstrated in this work, we restrict ourselves to the initial 250 as it allows us to compares against the prior 2 cases where we operate in a relatively data-scarce setting.

Figure 10. Error growth across time roll-out of the FNO in the physical space. The error in emulating each variable of the reduced MHD model increases as we roll further out in time.
Download figure:
Standard image High-resolution image3.1.4. Individual FNO vs multi-variable FNO.
MHDs governing the evolution of a plasma state is characterised by the amalgamation of Navier–Stokes equation of fluid dynamics and Maxwell's equations of electromagnetism [33]. The evolution of MHD fields involves modelling multi-physics environments with coupled variables that are integrated together. Considering this interplay of different field variables, it was imperative that we devise the multi-variable FNO, where all the interested and dependent variables can be modelled together.
Our multi-variable FNO, as described in section 2.3.3, achieves the required multi-physics modelling, with the same computational costs as training individual FNOs for each variable. The multi-variable FNO has approximately the same number of parameters as the different individual FNOs combined, and thus takes the same time as training two or three different FNO models. As shown in figure 11, the multi-variable FNO achieves better performance with much less error than the individual FNOs. Figure 11 demonstrates that by integrating the different field variables within the model, we can reduce the error associated with the autoregressive time rollout, dampening the error growth. It must be noted that since each variable has a different normalisation applied to it (the same scheme, but different normalisation), the comparison within the normalised domain is consistent within the same variable.

Figure 11. Comparing the error growth (mean absolute error in the normalised domain) of different variables across time roll-out of the Individual FNO (Single) and the Multi-variable FNO (Multi) for the various MHD cases under study. (a) Single Isothermal Blob (b) Single Blob with non-uniform temperature (c) Multi-blobs with non-uniform temperature. The multi-variable FNO with the same parameters as the individual FNOs demonstrates much better performance over time. The y-axis represents the mean absolute error for each case, and the x-axis represents the time iteration of the autoregressive rollout.
Download figure:
Standard image High-resolution imageThus, we conclude that for highly correlated multi-physics systems, such as those described by the MHD equations, multi-variable FNO, which captures the interdependence of the variables within a single model, yields a much more physically consistent result than the variables modelled individually by separate FNOs with no methods of exploiting the relationship across them.
3.1.5. Impact of step size.
The FNO, devised to be utilised in an autoregressive configuration, is only exposed to the first T_in time steps as inputs to the model. The rest of the inputs for emulating the time evolution are obtained by feeding back the output into the model in a recursive manner. The model follows the layout of a Markov decision process [34] as it relies on the previously generated time steps to provide all the information pertaining to the state of the system, without having a memory component attached to it. As the model trains, the autoregressive output generated from the input is compared against that of the simulation data to learn the mapping in a supervising manner. When deployed at inference, the FNO relies purely on the initial time steps to perform the time roll-outs of the plasma evolution.
Thus, the choice of the output size (step size), i.e, how much further in time the FNO predicts the time evolution with each forward pass, essentially provides disconnects across time for the model, which is evident by looking at figure 12. At each time step that is a multiple of the step size, we notice a spike in the cumulative error of the model. This spike denotes a disconnection that occurs as the model performs the autoregressive time evolution. In figure 12, the orange line indicates the error growth for a step size of 1, where there is no spike characterising the disconnection. For the red line with a step size of 5, we notice that there is a spike at every 5th time step starting form 10 and similarly for the green line indicative of models with a step size of 10, the spike is observed at every 10th time step. Throughout the scope of this study for surrogate modelling plasma simulations, we restrict ourselves to step size = 5 as we find it offers the best training efficiency, optimum performance with less computational time.

Figure 12. Comparing the cumulative error growth of different variables across time roll-out for multi-variable FNOs with different step sizes. The autoregressive nature of the FNO brings about a spike in error, characterising a disconnection at the time step that is a multiple of the output size. (a) Isothermal blob (b) Single blob with non-uniform temperature (c) Multi-blobs with non-uniform temperature. The y-axis represents the mean absolute error for each case, and the x-axis represents the time iteration of the autoregressive rollout.
Download figure:
Standard image High-resolution imageRegardless of this error spike, the FNO performs well in (surrogate) modelling the various MHD cases under study. We notice that the multi-variable FNO with a step size of 1 performs the best with a smooth and dampened error growth. This is expected as the network parameters are being used to perform mapping for one time step rather than several steps, effectively providing more parameters per step. We notice that the error decreases initially before it increases and believe it is because of the autoregressive structure of the training regime. In forward propagation, the model uses the time step data first from the data and then from the model itself. This results in a distribution shift problem because the inputs are no longer solely from ground truth data, the distribution learned during training will always be an approximation of the true data distribution [35]. The pushforward trick demonstrated in [36], offers an alternative training regime that allows us to account for this behaviour.
3.1.6. Mode ablations.
The Fourier integral operator within the Fourier layer of the FNO truncates the Fourier series up to a maximal number of modes  [27]. This presents an additional hyperparameter to each Fourier layer of the FNO that determines the extent to which Fourier modes are required to be learned to map the spatio-temporal evolution. Within our experiments, we ensure that for each multi-variable FNO, the modes at each Fourier layer are fixed. Figure 13 shows the impact the number of modes has on the FNO in emulating the MHD case with multiple density and temperature blobs (Case 3). For a smaller number of modes, the FNO demonstrates a higher error value at each time step, whereas for higher mode numbers, we notice that the error is relatively lower. We also notice that the performance of the FNO plateaus at 8 modes and does not increase further as the mode numbers are increased. This arises due to the fact that the dominant features that are characteristic of the system we are learning saturates at the 8th
mode, and no more dominant features are found at higher modes for the multi-blob case. This is consistent with the mode selection that one has to perform for each problem that a neural operator is applied to. The effect of this is studied in detail [37].
[27]. This presents an additional hyperparameter to each Fourier layer of the FNO that determines the extent to which Fourier modes are required to be learned to map the spatio-temporal evolution. Within our experiments, we ensure that for each multi-variable FNO, the modes at each Fourier layer are fixed. Figure 13 shows the impact the number of modes has on the FNO in emulating the MHD case with multiple density and temperature blobs (Case 3). For a smaller number of modes, the FNO demonstrates a higher error value at each time step, whereas for higher mode numbers, we notice that the error is relatively lower. We also notice that the performance of the FNO plateaus at 8 modes and does not increase further as the mode numbers are increased. This arises due to the fact that the dominant features that are characteristic of the system we are learning saturates at the 8th
mode, and no more dominant features are found at higher modes for the multi-blob case. This is consistent with the mode selection that one has to perform for each problem that a neural operator is applied to. The effect of this is studied in detail [37].

Figure 13. Ablation study of multi-variable FNOs with different truncated mode numbers. Error growth of FNOs with different mode numbers as they are autoregressively evolved in time for the Multiblob case. Errors decrease with a higher number of modes, and performance nearly plateaus at higher modes, indicating the existence of dominant features for the problem up to a certain number of modes. For each model, the width of the temporal channel was fixed at 32, and that of the variable channel was fixed at 3.
Download figure:
Standard image High-resolution imageWithin the mode ablation study, we notice that at lower modes, though the error of the model is higher, it produces smoother field profiles than those at higher modes. In figure 14, we see that the FNO with 2 modes, generates fields that are smoother and less noisy, especially at the initial time steps. However, they soon lose the general structure as they progress further in time. In the FNO with higher modes ( = 8, 32), the FNO output is much noisier than those at lower modes, but preserves the general structure of the temporal evolution better.
= 8, 32), the FNO output is much noisier than those at lower modes, but preserves the general structure of the temporal evolution better.

Figure 14. Evolution of the electric potential (Multiblobs) in time as modelled by multi-variable FNOs at different modes. Top row of (a) shows the actual solution modelled using JOREK. The bottom row of (a), plots the time evolution of the FNO with 2 modes, top row of (b) is that of a model with 8 modes, and the bottom row of (b) is the FNO with 32 modes. FNO with lower modes produce less noise, but fail to predict the longer evolution structures, while those with higher modes are inherently noisier and capture the long-term predictions better.
Download figure:
Standard image High-resolution image3.1.7. Impact of training dataset size.
Figure 15 visualises the impact the size of the training dataset has on the performance of the multi-variable FNO. For this purpose, we generate a larger dataset using the same scheme as given in table 1. We generate a total of 1835 JOREK simulation data points, out of which we set aside 85 as the test dataset. We train multiple multi-variable FNOs with training sizes ranging from 250 to 1750 simulations and compare their performance on the test dataset. All the models are constructed and trained under identical conditions, with the exception of the training data. We find that the performance of the FNO increases as we increase the training size, with model error decreasing by nearly half. However, we notice the gains made by added simulation data do not scale well at all. As shown in figure 15, improvement in performance is only marginal in comparison to the added computational costs associated with the training as well as the simulation run times. This is further illustrated in the loss curves of each associated experiment shown in figure 16.

Figure 15. Impact of the size of the training dataset on the performance of the multi-variable FNO for simulating the multiple plasma blobs in a non-uniform temperature field. As we increase the availability of the training data for the multi-variable FNO, the model performance increases across the same test data. However, the gains obtained by increasing the training data are marginal compared to the additional compute required. The number of simulations used for training is given on the x-axis while the mean squared error is given on the y-axis. All training is performed on a single Nvidia A100.
Download figure:
Standard image High-resolution image
Figure 16. Learning curves associated with the models trained with data of different sizes. Training loss is represented by full lines, while the test loss is represented by dashed lines. With just 500 simulation instances, the model learns the physics of the model really well, which is only marginally improved by more training data. We also notice the quick over-fitting tendency of the FNO as observed in [38].
Download figure:
Standard image High-resolution image3.1.8. Zero-shot super-resolution.
As described in section 2.3, the NO framework allows learning within the function space as opposed to the Euclidean space as with traditional neural networks [13]. By learning the mapping between infinite-dimensional function spaces, the framework performs operator learning, allowing for characterising discretisation within our model. Within the FNO, discretisation invariance is built in by learning within the Fourier space rather than the Euclidean space on which the solutions exist, as demonstrated in equation (8). Being discretisation-convergent, the FNO learns information up to a certain refinement of the mesh resolution, higher than what we had provided in the initial training dataset [15]. The truncated nature of the FNO characterises the model as a band-limited function. Coupled with the discrete modal representation in the Fourier space, the FNO converges to a fixed performance at higher resolution [15].
This discretisation-convergence allows us to perform zero-shot super-resolution, trained on a lower resolution, and directly evaluated on a higher resolution [27]. In figure 17, we demonstrate this capability for zero-shot super-resolution, where we take the model trained on a spatial discretisation of  used for the prior experiments and then deploy it to emulate the evolution of multiple blobs at a spatial discretisation of
used for the prior experiments and then deploy it to emulate the evolution of multiple blobs at a spatial discretisation of  . Even for grids at 5 times larger resolution, the FNO is capable of emulating the plasma with considerable accuracy, deviating from the true solution by an MSE (in the normalised domain)of only
. Even for grids at 5 times larger resolution, the FNO is capable of emulating the plasma with considerable accuracy, deviating from the true solution by an MSE (in the normalised domain)of only  in the normalised domain. They share the same model parameters among different discretisations of the underlying function space that we are attempting to learn. Plots showing the contrast of the super-resolved FNO output with that of JOREK by way of discrepancy plots can be found in figure A6 in appendix
in the normalised domain. They share the same model parameters among different discretisations of the underlying function space that we are attempting to learn. Plots showing the contrast of the super-resolved FNO output with that of JOREK by way of discrepancy plots can be found in figure A6 in appendix

Figure 17. Demonstrating Zero-Shot Super-Resolution on the multi-variable FNO. The FNO being trained on a grid resolution of  is further deployed to model the evolution the the multiple blobs at a resolution of
is further deployed to model the evolution the the multiple blobs at a resolution of  . The model is capable of performing zero-shot super-resolution, achieving an MSE(in the normalised domain) of
. The model is capable of performing zero-shot super-resolution, achieving an MSE(in the normalised domain) of  at a grid resolution 5 × more resolved than the one it was being trained on without the requirement of any model engineering or fine-tuning. The plots demonstrate the evolution of density, electric potential, and temperature as emulated by the FNO. For plots (a), (b), and (c), the top series of plots demonstrate the time evolution of the ground truth while the bottom series of plots demonstrate the time evolution as emulated by the multi-variable FNO.
at a grid resolution 5 × more resolved than the one it was being trained on without the requirement of any model engineering or fine-tuning. The plots demonstrate the evolution of density, electric potential, and temperature as emulated by the FNO. For plots (a), (b), and (c), the top series of plots demonstrate the time evolution of the ground truth while the bottom series of plots demonstrate the time evolution as emulated by the multi-variable FNO.
Download figure:
Standard image High-resolution image3.1.9. Extrapolating outside training domain.
Neural Networks trained for modelling a particular task have been found to suffer from a general lack of extrapolation capabilities [39]. The FNO relying on a continuous gradient-descent based optimisation of the deep learning parameters exhibit the same behaviour. The models perform well within the domain of the training data, as can be explained by the associated Neural Tangent Kernels (NTK) [40] and fail to perform well outside the training regime.
For our multi-variable FNO that models the evolution of multiple blobs in reduced MHD, we can empirically validate the above-mentioned statements. When inferred on a case where there are 13 blobs with amplitude and density twice more and width 1.5 times more than the maximum used within the training data, we observe that the FNO can model the plasma evolution at the earliest prediction time instance and fails to capture the evolution of the plasma behaviour further in time as evidenced in the figure 18.

Figure 18. Outside the training domain: Inferring on a case with 13 blobs with amplitude and density twice more and the blob width 1.5 times more than the maximum used within the training data (see table 1). Temporal evolution of (a) density (b) electric potential and (c) temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution image3.1.10. Scaling to 3D.
There exist several challenges in the extending the FNO to model the evolution of multi-variable PDEs to 3D settings. The primary concern is of the memory constraints needed for a 3D multi-variable FNO when being evaluated autoregressively in time, leading to GPU bottlenecks. Recent work in performing Tensor factorisation over the FNO weights, allows representing the network in a lower rank approximation [41], offers potential to those GPU training bottlenecks.
Another challenge associated with the scaling is that of the computational costs associated with data generation. In 3D, the numerical solvers that generate the training datasets are exponentially more intensive than in the 2D settings, limiting the amount of training data that could be generated. Deploying Active Learning (AL) methods, which allow for more informed sampling of the parameter domain space offers a solution to this. Within AL, the model is initially trained on a coarsely sampled, limited dataset and then evaluated across the interested domain. Performance (or uncertainty) of the model within the interested domain informs the next data generation points, which are added to the training data, improving the model accuracy. AL allows the model to maximise performance, minimise uncertainty within data scarce scenarios [42]. Within the scope of plasma physics, AL has been found to reduce the data requirement of surrogate models by a factor of 20 in modelling Gyrokinetic Turbulence [43]. The issue of data-scarcity arising from the profound computational intensiveness of 3D simulations could also be combat by using physics-informed models, where the information regarding the PDE is hard-baked into the model architecture or the training regime. Recent works on physics informed neural operators has shown promise in fine-tuning coarsely trained models with PDE constraints within MHD scenarios [44].
While scaling to 3D settings it might be the case that the choice of operator within the Neural Operator might be limiting and not representative of the true solution, thus there might be a requirement of a combination of different operators implemented over different families of basis functions within the model to account for the varied physics that is found within the PDEs. One last challenge to consider is that proposed by the autoregressive layout of the FNO. The addition of another dimension will contribute further to the error growth in time as noted in figure 10. Though this remains a standing problem within the domain of Neural-PDEs, recent works have shown promise in solving this challenge by providing further conditioning of the longer time roll-outs [45].
3.2. FNO over MAST camera
As described in section 2.2, we conduct exploratory research in looking at using the FNO as an emulator for performing predictive inference in real-time of the plasma evolution within the MAST fusion device. For this purpose, we deploy FNOs with the same architecture as that used for emulating the Individual FNOs (given under appendix
In the case of the MHD simulations, the evolution of plasma is a Markovian Process, with no element of noise found within the dataset. However, within the case of the experimental data, the images are still time-series data, but they are non-markovian, noisy, and represent only partial information about the state of the system. In addition, the dataset does not offer any information about the causal contributors, such as the various control inputs that influence the state of the system, and is assumed to be implicitly defined within the time evolution of the data. Taking this into account, implementing an autoregressive structure as demonstrated in [18], provided limited capabilities as the error growth across the time roll-out would be too large, not allowing us to perform longer time roll-outs. Within the scale of the experimental data, it might be the case that there might be new information fed into the system midway through it. By utilising an autoregressive rollout that relies solely on the initial time steps, the model will not be able to account for this new information added later to the system. Unlike in the case of modelling simulations, there is no actual need within the experimental space to rely just on the initial conditions and state of the system to perform the prediction. Data characterising the temporal evolution of the plasma is generated and captured by the diagnostic as the experiment is run and does not need any additional intervention to obtain it. Our training and inference setup takes advantage of this continuously generated data to build our predictive model.
Instead of performing an autoregressive time rollout, we perform a fixed time window mapping (as outlined in figure figure 5), where the FNO takes in the camera information for fixed time steps (T_in) and outputs the next set of frames characterising the future plasma state (step). Being trained in this sequential pipeline, the model initially takes in the first 10 time instances (1–10 frames) to output the next 10 time instances (11–20 frames). With the next forward pass, the model takes in the other 10 time instances, but this time, forward by one frame (2–11 frames) to predict the next 10 frames to that input (12–21 frames). This input, characterised by a 10-frame window slid by one each forward pass, is run until we output the last required frame (T_out). Our trained FNO models the plasma at ramp-up, entering the flat-top regime, and in most cases, across the L-Mode and H-Mode operational regimes, covering the full (available) plasma duration. Since we are designing this to be run in real-time with the experiment, future time windows, as they become available, will be fed into the model to predict the future plasma states. The time resolution of the fast camera diagnostic is 1.2 ms, where the FNO only requires 6 ms to predict the next 12 ms of the plasma evolution, allowing us to run the model efficiently in real time.
Even though we keep our focus on a limited number of shots curated according to the criteria given in section 3.2.1, as we structure them into input-output pairs by way of the sliding windows as described above, we essentially turn each shot characterising of approximately 200 frames into 180 input-output pairs. The FNO is exposed to dynamics of the plasma evolution across the interested time window of MAST operation, learning to predict from any intermediary states of the system to the next states of the system. The FNO is trained to learn how to predict the evolution of the plasma as witnessed by the camera for the full (available) range of operation of the Tokamak pulse.
For each camera FNO, we chose the input feed to consist of 10 time steps of the field information (T_in = 10), with an output size of 10 (step = 10). Each Fourier layer within the FNO has 8 modes and a temporal channel width of 16. The grid discretisation associated with the field data (obtained from the reactor CAD model) is added to the training data within each model's forward call as an addition to the temporal channel, providing further field information to the model. The data is normalised by following a linear range scaling, allowing the field values to lie between −1 and 1. Each model is trained for 500 epochs using the Adam optimiser [32] with a step-decaying learning rate. The learning rate is initially set to 0.005 and scheduled to decrease by half after every 100 epochs. The model was trained using a Relative L2 loss function over the reconstruction error alone (see equation (11)).
3.2.1. Data selection.
Throughout this study, we work on a selected number of plasma shots for each cameras, restricting ourselves to the M9 campaign on MAST. For the rbb camera, we restrict ourselves to 55 shots lying within the range: 30 250–30 431 from the MAST experimental database. For the rba camera we look at 48 shots lying within the same range 30 250–30 431. The shots were carefully curated from the above shot range by considering several factors. The first criterion was to ensure that the selected shot actually contained a confined plasma and was not a dummy shot like commissioning pulses. The second criterion was whether the shot had the desired duration of more than 100 time steps—looking at forecasting longer-term plasma evolution. The third one was selecting shots within the above-mentioned ranges that had the same camera calibration. Considering the FNO relied on a grid discretisation to leverage the Fourier modes, it was crucial to ensure that the pixels from the camera belonged to the same line of sight vectors. The camera calibrated for specific experimental runs captures the information of the plasma onto a uniform pixel grid, allowing us to perform Fourier transformations over them. By using calcam, a calibration tool developed by the European Atomic Energy Community [46] combined with 3D CAD models of MAST, we determine the domain range covered by each camera calibration. The upper and lower limits of the domain range of these images are then fixed onto uniform grids in both the R and Z axis, allowing us to create uniform grid discretisations underlying each camera image. The last criterion was to ensure that the camera images obtained from the diagnostic had the same spatial resolution across the dataset that could be fed into the FNO. For the rbb camera, we chose the shots with a resolution of ( ), and for the rbb camera, we chose those with the resolution (
), and for the rbb camera, we chose those with the resolution ( ). However, the FNO offers discretisation convergence, the training setup benefits greatly from ensuring coherence along the spatial resolution. Figure 19 shows the plasma signals allows to demonstrate the diversity of the scenarios used to train and test the FNO modelling the cameras. The training data consists of multiple different scenarios, allowing for building a general model. However, the test data is selected to be largely representative of the scenarios found within the training data. For a full list of the selected shots, refer appendix
). However, the FNO offers discretisation convergence, the training setup benefits greatly from ensuring coherence along the spatial resolution. Figure 19 shows the plasma signals allows to demonstrate the diversity of the scenarios used to train and test the FNO modelling the cameras. The training data consists of multiple different scenarios, allowing for building a general model. However, the test data is selected to be largely representative of the scenarios found within the training data. For a full list of the selected shots, refer appendix

Figure 19. Temporal plots of (a) Plasma Current and (b) Total Heating Power of the shots selected for training and testing the FNO for modelling the camera data. The shots depicting the training data is given in black, whereas the test data is given in red. The plots help convey the diversity of plasma scenarios the FNO is trained to model over. The training data consists of multiple different scenarios, allowing for building a general model. However, the test data is selected to be largely representative of the scenarios found within the training data.
Download figure:
Standard image High-resolution image3.2.2. Camera viewing the central solenoid (rbb).
The evolution of the plasma within the Tokamak, as seen by the main camera, can be shown in figure 20. The plot shows the comparisons of the evolution as observed by the FNO with that of the camera spanning 10 frames predicted in one feed-forward iteration. The central solenoid serves as the backbone of the MAST magnet system, generating the majority of the magnetic fluxes as well as the plasma current. In figure 23, we portray the predictive capability of the FNO by comparing the last frame from multiple feed-forward instances taken from data across the interested length of the pulse. This allows us to compare that even for the longest time prediction, we can get reasonable predictions. In figure 23, we demonstrate that the FNO is capable of predicting the plasma in L-mode as well as in H-mode, characterising the plasma evolution across the full (available) range of the plasma shot. The main camera view, as shown in figure 1 provides a panoramic view of the reactor, showing the poloidal cross-sectional layout on both sides of the central solenoid. The main camera has a spatial resolution of  for the experiments that we sampled. We sampled a total of 55 plasma shots from the MAST database, used 50 for training and 5 for testing. Once we structure the data into windowed input-output pairs, the training size of the dataset grows to 7661, and the test points grow to 828 data points. The model takes 27 h 45 min on a Nvidia A100 chip. With the above-mentioned training configuration, the model achieves an MSE (in the normalised domain) of
for the experiments that we sampled. We sampled a total of 55 plasma shots from the MAST database, used 50 for training and 5 for testing. Once we structure the data into windowed input-output pairs, the training size of the dataset grows to 7661, and the test points grow to 828 data points. The model takes 27 h 45 min on a Nvidia A100 chip. With the above-mentioned training configuration, the model achieves an MSE (in the normalised domain) of  . For further plots showcasing the forecasting capabilities of the FNO at the plasma around the central solenoid, refer to appendix
. For further plots showcasing the forecasting capabilities of the FNO at the plasma around the central solenoid, refer to appendix

Figure 20. Predicting in L-mode: Temporal evolution of the plasma around the central solenoid within MAST as perceived by the main camera with the plasma in L-mode. The image compares the plasma evolution across one feed-forward operation of the FNO spanning 10 frames ∼12 ms. The top layer shows the actual data obtained from the experiment. The middle layer displays the emulation performed by the FNO. The bottom layer showcases the absolute error across the prediction and the camera.
Download figure:
Standard image High-resolution imageThe FNO deployed with the time-window pipeline (see figure 5), is able to capture the long-term dependencies that arise within the plasma confinement. The model is able to predict the evolution of the plasma from L-mode to H-mode as seen in figure 23. The prediction around the transition regime can be seen in Though the camera captures the confined plasma shape, it fails to capture the localised filaments. In figure 20, the trained FNO is deployed to model the evolution of plasma within the L-Mode of operation, whereas in figure 21 the FNO is modelling the region of H-mode within the same plasma shot.

Figure 21. Predicting in H-mode: Temporal evolution of the plasma around the central solenoid within MAST as perceived by the main camera wiht the plasma in H-mod. The image compares the plasma evolution across one feed-forward operation of the FNO spanning 10 frames ∼12 ms. The domain is selected to showcase the performance of the FNO in mapping the plasma evolution in H-mode. The top layer shows the actual data obtained from the experiment. The middle layer displays the emulation performed by the FNO. The bottom layer showcases the absolute error across the prediction and the camera.
Download figure:
Standard image High-resolution imageThe capability of the FNO in predicting across the L-H transition is further emphasised through figure 22, where we show the prediction around the transition region for shot number 30 428. We provide the camera image, FNO prediction and the absolute error at L-mode (162 ms), around the transition (172 ms) and with the plasma in H-mode (186 ms). The FNO is capable of modelling the plasma in both L-mode, H-mode and across the transition, but as the FNO is a regression model and not a classification model, without further analysis over the predicted solution, the model is unable to explicitly mention that it is capable of predicting the exact moment of transition. This will be a key area of focus for the next research avenue.

Figure 22. Predicting around the L-H transition: Temporal evolution of the plasma around the central solenoid within MAST as perceived by the main camera. The image compares the last frame of the predicted plasma evolution across multiple feed-forward instances across the duration of the pulse. The top layer shows the actual data obtained from the experiment, the middle layer displays the emulation performed by the FNO. The bottom layer showcases the absolute error across the prediction and the camera. Though the camera captures the confined plasma shape, it fails to capture the localised filaments.
Download figure:
Standard image High-resolution image
Figure 23. Long-term prediction: Temporal evolution of the plasma around the central solenoid within MAST as perceived by the main camera. The image compares the last frame of the predicted plasma evolution across multiple feed-forward instances across the duration of the pulse. The top layer shows the actual data obtained from the experiment, the middle layer displays the emulation performed by the FNO. The bottom layer showcases the absolute error across the prediction and the camera. Though the camera captures the confined plasma shape, it fails to capture the localised filaments.
Download figure:
Standard image High-resolution image3.2.3. Camera viewing the divertor (rba).
The evolution of the plasma within the Tokamak as seen by the divertor camera, along with predicted images from the FNO can be seen in figure 24. The plot shows the comparisons of the evolution as observed by the FNO with that of the camera spanning 10 frames predicted in one feed-forward iteration. The divertor of a Tokamak serves as the exhaust of the device, where the topology of the magnetic flux surfaces is designed to isolate the confined plasma from the first-wall of the device. In figure 25, we portray the predictive capability of the FNO by comparing the last frame from multiple feed-forward instances taken from data across the interested length of the pulse, demonstrating the predictive power of the FNO. The divertor camera looks at the lower divertor of MAST with a spatial resolution of  . We sampled a total of 48 plasma shots from the MAST database, used 45 for training and 3 for testing. Once we structure the data into windowed input-output pairs, the training size of the dataset grows to 5815, and the test points grow to 701 data points. The model takes 9 hours 10 minutes on a Nvidia A100 chip. With the above-mentioned training configuration, the model achieves an MSE (in the normalised domain) of
. We sampled a total of 48 plasma shots from the MAST database, used 45 for training and 3 for testing. Once we structure the data into windowed input-output pairs, the training size of the dataset grows to 5815, and the test points grow to 701 data points. The model takes 9 hours 10 minutes on a Nvidia A100 chip. With the above-mentioned training configuration, the model achieves an MSE (in the normalised domain) of  . For further plots showcasing the fore- casting capabilities of the FNO at the divertor plasma, refer to appendix
. For further plots showcasing the fore- casting capabilities of the FNO at the divertor plasma, refer to appendix

Figure 24. Single forward pass: Temporal evolution of the plasma at the divertor within MAST as perceived by the divertor camera. The image compares the plasma evolution across one feed-forward operation of the FNO spanning 10 frames ∼12 ms. The top layer shows the actual data obtained from the experiment. The middle layer displays the emulation performed by the FNO. The bottom layer showcases the absolute error across the prediction and the camera.
Download figure:
Standard image High-resolution image
Figure 25. Long-term prediction: Temporal evolution of the plasma at the divertor within MAST as perceived by the divertor camera. The image compares the last frame of the predicted plasma evolution across multiple feed-forward instances across the duration of the pulse. The top layer shows the actual data obtained from the experiment. The middle layer displays the emulation performed by the FNO. The bottom layer showcases the absolute error across the prediction and the camera.
Download figure:
Standard image High-resolution imageThe FNO deployed for emulating the camera data accurately preserves the global features of the plasma evolution. It is able to clearly characterise the locations and intensities of the heat fluxes onto the solenoid and the divertors, allowing us to anticipate the heat flux in advance and initiate the appropriate actuator mechanism to minimise its impact on the various plasma-facing components. The FNO also captures the reflections generated within the device due to the interactions across the plasma and the plasma-facing components. The FNO, in its current form, smooths out the filaments but captures the general confined structure of the plasma as it evolves in time. As expected, the FNO learns characteristics extremely well, while failing to capture the localised phenomena with matching pixel-pixel accuracy.
3.2.4. Limitations.
We decided to look at a narrow shot corridor, since the data variability will be low, allowing us to demonstrate a functioning proof-of-concept. Our predictive model only takes in the camera diagnostic as the input and does not take into account any of the control signals, such as coil currents and heating parameters that influence the plasma evolution. However, we argue that within the past window of plasma observed from the camera data that is taken as the input, these control parameters and their influence are implicitly defined (with a latency), and thus, the model provides a suitable predictive tool for short-term predictions. The inclusion of various control signals, time matched with the camera inputs, will potentially help improve the performance of the model. Our future research trajectory will be heading in this direction.
4. Conclusion and discussion
Through this work, we demonstrate the utility of using the FNO as both a surrogate model for a plasma simulator and as a predictive emulator for a plasma experiment. We design a modified version of the FNO, that performs integrated emulation of multiple variables associated with a family of PDEs. Our analysis across a range of reduced MHD cases demonstrates that even in data-scarce scenarios, the FNO can be trained to act as a surrogate. Through this paper, we highlight the various features that make the FNO a natural choice for (surrogate) modelling MHD cases, all the while performing ablation studies on the various hyperparameters and the training regimes. We find that the FNO fits the requirements of a quick, cheap surrogate, but due to its auto-regressive nature, fails to capture the physics when deployed for long time roll-outs. Being utilised for emulating the experiment, the FNO is capable of forecasting the evolution of the plasma as seen through the cameras on a fusion device. The FNO camera models are capable of identifying the regions of plasma interaction with the central solenoid and the divertor, while effectively predicting the plasma shape evolution. The FNO has shown versatile performance in being able to model the plasma confinement across both L-mode and H-mode of plasma operation across a diverse range of shots. The FNO for the camera can predict the plasma evolution in real-time and offers us the potential to be deployed within the planning stage for various control scenarios. Our work also demonstrates how we can perform zero-shot super-resolution across the pre-trained multi-variable FNO and obtain the plasma emulation at higher resolutions than it was trained on, without requiring any fine-tuning.
In continuing with this line of work, we will be exploring the utility of building more versatile and robust FNO models that can be deployed not just in a particular case, but across a range of simulation cases. While we build more general MHD models, we will also be looking at methods to better physics-inform the models [14], allowing us to fine-tune the general models to specific MHD instances. We will also be looking into methods of quantifying the uncertainty associated with the surrogate models and into AL pipelines that can facilitate the entire surrogate ecosystem. With the FNO for camera data, we are currently working on extending the utility across more plasma shots with a more diverse line of sights, across multiple campaigns while exploring the utility of state space models for longer predictions [47]. The work will be looking at including various control signals, to help improve the performance of the real-time predictive emulator for the MAST Tokamak, performing longer forecasting.
Appendix A: Error plots
A.1. Single Blob with uniform Temperature

Figure A1. Isothermal Blob : Temporal evolution of (a) the density and (b) the potential of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution imageA.2. Single blob with non-uniform temperature

Figure A2. Single Blob with non-uniform Temperature: Temporal evolution of (a) the density and (b) the potential, (c) the Temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution imageA.3. Multiple blobs with non-uniform temperature

Figure A3. Multiple Blobs with non-uniform temperature: Temporal evolution of (a) the density and (b) the potential, (c) the Temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution image
Figure A4. Multiple Blobs with non-uniform temperature: Temporal evolution of (a) the density and (b) the potential, (c) the Temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution image
Figure A5. Multiple Blobs with non-uniform temperature: Temporal evolution of (a) the density and (b) the potential, (c) the Temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis.
Download figure:
Standard image High-resolution image
Figure A6. Demonstrating Zero-Shot Super-Resolution on the multi-variable FNO. The FNO being trained on a grid resolution of  is further deployed to model the evolution the the multiple blobs at a resolution of
is further deployed to model the evolution the the multiple blobs at a resolution of  . The model is capable of performing zero-shot super-resolution, achieving an MSE (in the normalised domain) of
. The model is capable of performing zero-shot super-resolution, achieving an MSE (in the normalised domain) of  at a grid resolution 5 × more resolved than the one it was being trained on without the requirement of any model engineering or fine-tuning. The plots demonstrate the evolution of density, electric potential, and temperature as emulated by the FNO. For plots (a), (b), and (c), the top series of plots demonstrate the time evolution of the ground truth while the middle series of plots demonstrate the time evolution as emulated by the multi-variable FNO and the bottom series indicates the absolute error across space.
at a grid resolution 5 × more resolved than the one it was being trained on without the requirement of any model engineering or fine-tuning. The plots demonstrate the evolution of density, electric potential, and temperature as emulated by the FNO. For plots (a), (b), and (c), the top series of plots demonstrate the time evolution of the ground truth while the middle series of plots demonstrate the time evolution as emulated by the multi-variable FNO and the bottom series indicates the absolute error across space.
Download figure:
Standard image High-resolution imageAppendix B: Multi-variable FNO architecture
The architecture of the multi-variable FNO deployed in an auto-regressive manner for emulating the Reduced MHD equations. The model initially lifts the input data into a higher dimensional space using a linear layer. This is followed by 6 Fourier layers that learn the necessary modal mappings within the spatial domain, before being projected onto the lower dimensional space by a series of linear layers. Fourier 2d represents the 2D Fourier operator, features only extracted within the spatial domain, Conv3d represents the 3D convolutional layer across the variable channel and the spatial domain, hinzufügen operation adds the outputs from the Fourier layer and the convolutional layer together, GELU denotes the activation function: Gaussian Error Linear Unit.
Table B1. Architecture of the Multi-variable FNO deployed for emulating Reduced MHD.
| Part | Layer | Output Shape |
|---|---|---|
| Input | — | (10, 3, 100, 100, 12) |
| Lifting | Linear | (10, 3, 100, 100, 32) |
| Fourier 1 | Fourier2d/Conv3d/Add/GELU | (10, 3, 32, 100, 100) |
| Fourier 2 | Fourier2d/Conv3d/Add/GELU | (10, 3, 32, 100, 100) |
| Fourier 3 | Fourier2d/Conv3d/Add/GELU | (10, 3, 32, 100, 100) |
| Fourier 4 | Fourier2d/Conv3d/Add/GELU | (10, 3, 32, 100, 100) |
| Fourier 5 | Fourier2d/Conv3d/Add/GELU | (10, 3, 32, 100, 100) |
| Fourier 6 | Fourier2d/Conv3d/Add/GELU | (10, 3, 32, 100, 100) |
| Projection 1 | Linear | (10, 3, 100, 100, 128) |
| Projection 2 | Linear | (10, 3, 100, 100, 5) |
Appendix C: Long time roll-outs

Figure C1. Long Term roll-outs of Multiple Blobs with non-uniform temperature: Temporal evolution of (a) the density and (b) the potential, (c) the Temperature of the plasma evolution as obtained using the JOREK code (top of each image), that of the trained multi-variable FNO (middle of each figure) and the absolute error across both (bottom of each figure). The spatial domain is given in toroidal geometry characterised by R in the x-axis and Z in the y-axis. This model is trained to solve for up to 200 time instances, the full (available) scale of the simulation that we are interested in. Within the autoregressive roll-outs, the model quickly loses grip of the spatio-temporal dynamics as it accumulates further errors, leading to a noisy, incoherent output.
Download figure:
Standard image High-resolution imageAppendix D: Camera FNO architecture
The architecture of the Individual FNO deployed in an auto-regressive manner for emulating the Camera data. The model initially lifts the input data into a higher dimensional space using a linear layer. This is followed by 6 Fourier layers that learn the necessary modal mappings within the spatial domain, before being projected onto the lower dimensional space by a series of linear layers. Fourier 2d represents the 2D Fourier operator, features only extracted within the spatial domain, Conv2d represents the 3D convolutional layer across the spatial domain, hinzufügen operation adds the outputs from the Fourier layer and the convolutional layer together, GELU denotes the activation function: Gaussian Error Linear Unit.
Table D1. Architecture of the Individual FNO deployed for emulating the rbb Camera Data.
| Part | Layer | Output Shape |
|---|---|---|
| Input | — | (50, 448, 640, 12) |
| Lifting | Linear | (50, 448, 640, 16) |
| Fourier 1 | Fourier2d/Conv2d/Add/GELU | (50, 16, 448, 640) |
| Fourier 2 | Fourier2d/Conv2d/Add/GELU | (50, 16, 448, 640) |
| Fourier 3 | Fourier2d/Conv2d/Add/GELU | (50, 16 448, 640) |
| Fourier 4 | Fourier2d/Conv2d/Add/GELU | (50, 16, 448, 640) |
| Fourier 5 | Fourier2d/Conv2d/Add/GELU | (50, 16, 448, 640) |
| Fourier 6 | Fourier2d/Conv2d/Add/GELU | (50, 16, 448, 640) |
| Projection 1 | Linear | (50, 448, 648, 128) |
| Projection 2 | Linear | (50, 448, 648, 10) |
Table D2. Architecture of the Individual FNO deployed for emulating the rba Camera Data.
| Part | Layer | Output Shape |
|---|---|---|
| Input | — | (50, 400, 512, 12) |
| Lifting | Linear | (50, 400, 512, 16) |
| Fourier 1 | Fourier2d/Conv2d/Add/GELU | (50, 16, 400, 512) |
| Fourier 2 | Fourier2d/Conv2d/Add/GELU | (50, 16, 400, 512) |
| Fourier 3 | Fourier2d/Conv2d/Add/GELU | (50, 16 400, 512) |
| Fourier 4 | Fourier2d/Conv2d/Add/GELU | (50, 16, 400, 512) |
| Fourier 5 | Fourier2d/Conv2d/Add/GELU | (50, 16, 400, 512) |
| Fourier 6 | Fourier2d/Conv2d/Add/GELU | (50, 16, 400, 512) |
| Projection 1 | Linear | (50, 400, 512, 128) |
| Projection 2 | Linear | (50, 400, 512, 10) |
Appendix E: Camera at the central solenoid

Figure E1. Temporal evolution of the plasma around the central solenoid within MAST as perceived by the main camera. The image compares the last frame of the predicted plasma evolution across multiple feed-forward instances across the duration of the pulse.
Download figure:
Standard image High-resolution image
Figure E2. Temporal evolution of the plasma around the central solenoid within MAST as perceived by the main camera. The image compares the last frame of the predicted plasma evolution across multiple feed-forward instances across the duration of the pulse.
Download figure:
Standard image High-resolution imageAppendix F: Camera at the divertor

Figure F1. Temporal evolution of the plasma at the divertor within MAST as perceived by the divertor camera. The image compares the last frame of the predicted plasma evolution across multiple feed-forward instances across the duration of the pulse.
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure F2. Temporal evolution of the plasma at the divertor within MAST as perceived by the divertor camera. The image compares the last frame of the predicted plasma evolution across multiple feed-forward instances across the duration of the pulse.
Download figure:
Standard image High-resolution image{kind=link}
Appendix G: MAST Shots used for camera data
Shots used for the FNO modelling the plasma evolution as captured by the rbb camera looking at the central solenoid:
Training shots:
30 255, 30 256, 30 257, 30 258, 30 259, 30 260, 30 261, 30 262, 30 263, 30 264, 30 265, 30 266, 30 267, 30 269, 30 270, 30 290, 30 291, 30 298, 30 299, 30 301, 30 302, 30 303, 30 304, 30 305, 30 306, 30 338, 30 339, 30 342, 30 343, 30 345, 30 349, 30 350, 30 351, 30 352, 30 353, 30 354, 30 355, 30 356, 30 357, 30 358, 30 359, 30 360, 30 416, 30 417, 30 418, 30 419, 30 420, 30 421, 30 422, 30 423
Test shots:
30 424, 30 425, 30 426, 30 427, 30 428
Shots used for the FNO modelling the plasma evolution as captured by the rba camera looking at the divertor:
Training shots:
30 302, 30 353, 30 336, 30 266, 30 343, 30 252, 30 306, 30 256, 30 316, 30 322, 30 262, 30 356, 30 257, 30 317, 30 323, 30 263, 30 290, 30 352, 30 337, 30 253, 30 313, 30 359, 30 258, 30 338, 30 339, 30 269, 30 358, 30 259, 30 319, 30 299, 30 298, 30 270, 30 355, 30 345, 30 314, 30 260, 30 351, 30 264, 30 350, 30 301, 30 325, 30 265, 30 311, 30 360, 30 305
Test shots:
30 354, 30 255, 30 321