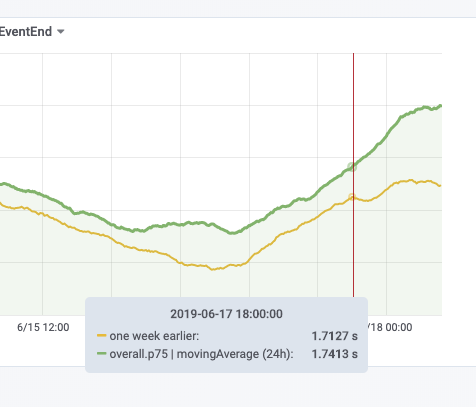
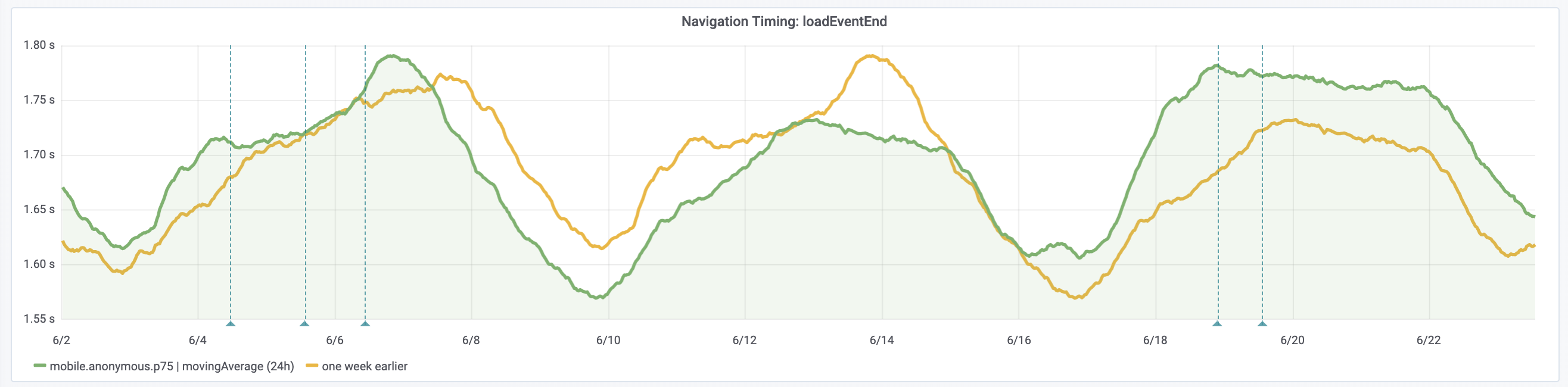
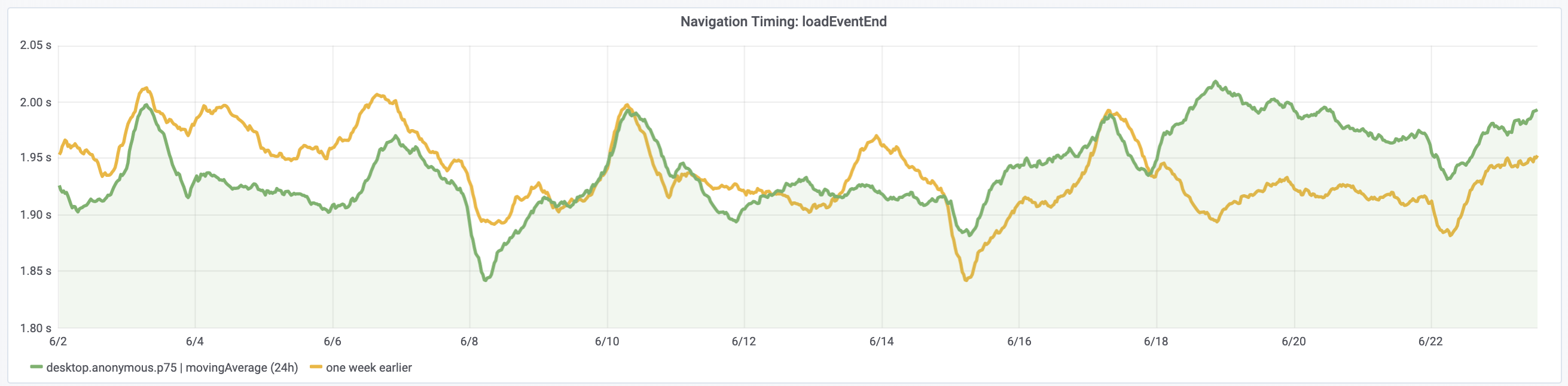
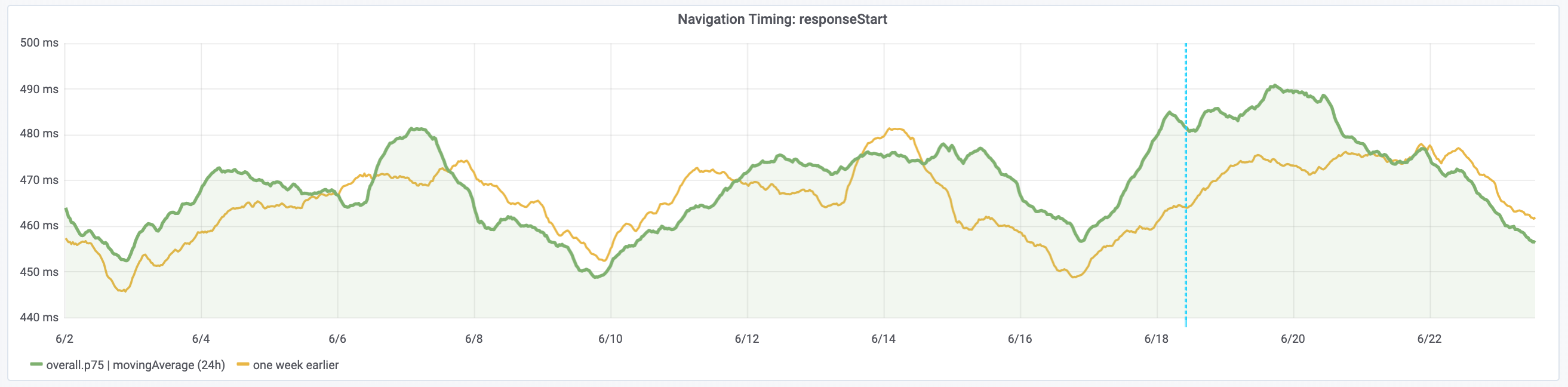
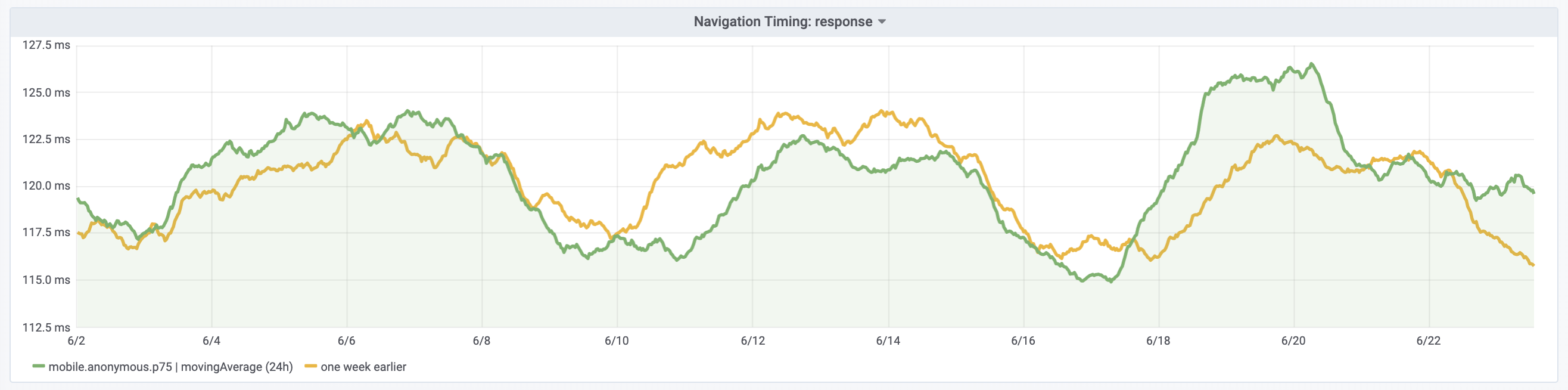
Yesterday we've disabled TCP SACKs [1] on the caches/bastions to mitigate a remote DoS in the TCP implementation in the Linux kernel [2].
The caches were disabled between 17:30 and 18:00 UTC on Mon 17th and the remaining hosts were disabled starting 8:20 UTC on Tue 18th (with Puppet runs taking up to 30 minutes after the merge of the patch).
Once a fixed kernel is fully deployed we can consider whether to re-enable TCP SACKs. Various options:
- If there's no visible performance impact, we can keep it disabled (reduces exploitable complexity)
- If there's a performance regression, re-enable on the caches only
- If there's a performance regression, re-enable fleet-wide if running a fixed Linux kernel (Puppet can apply this gradually as reboots happen)
Footnotes:
[1] https://en.wikipedia.org/wiki/Transmission_Control_Protocol#Selective_acknowledgments
[2] https://github.com/Netflix/security-bulletins/blob/master/advisories/third-party/2019-001.md