There has been an increase in varnish-be fetch failures in esams text lately, correlating timewise with T226048. FetchError monitoring, recently introduced, might help diagnosing the issue: T224994.
See the kibana dashboard https://logstash.wikimedia.org/goto/caa7c533400fa99e5a4b0516ee0298a6 as well as the fetcherror pie graph for a breakdown of the different errors: https://logstash.wikimedia.org/goto/f14da21012a25060b1f63685028ecc7b
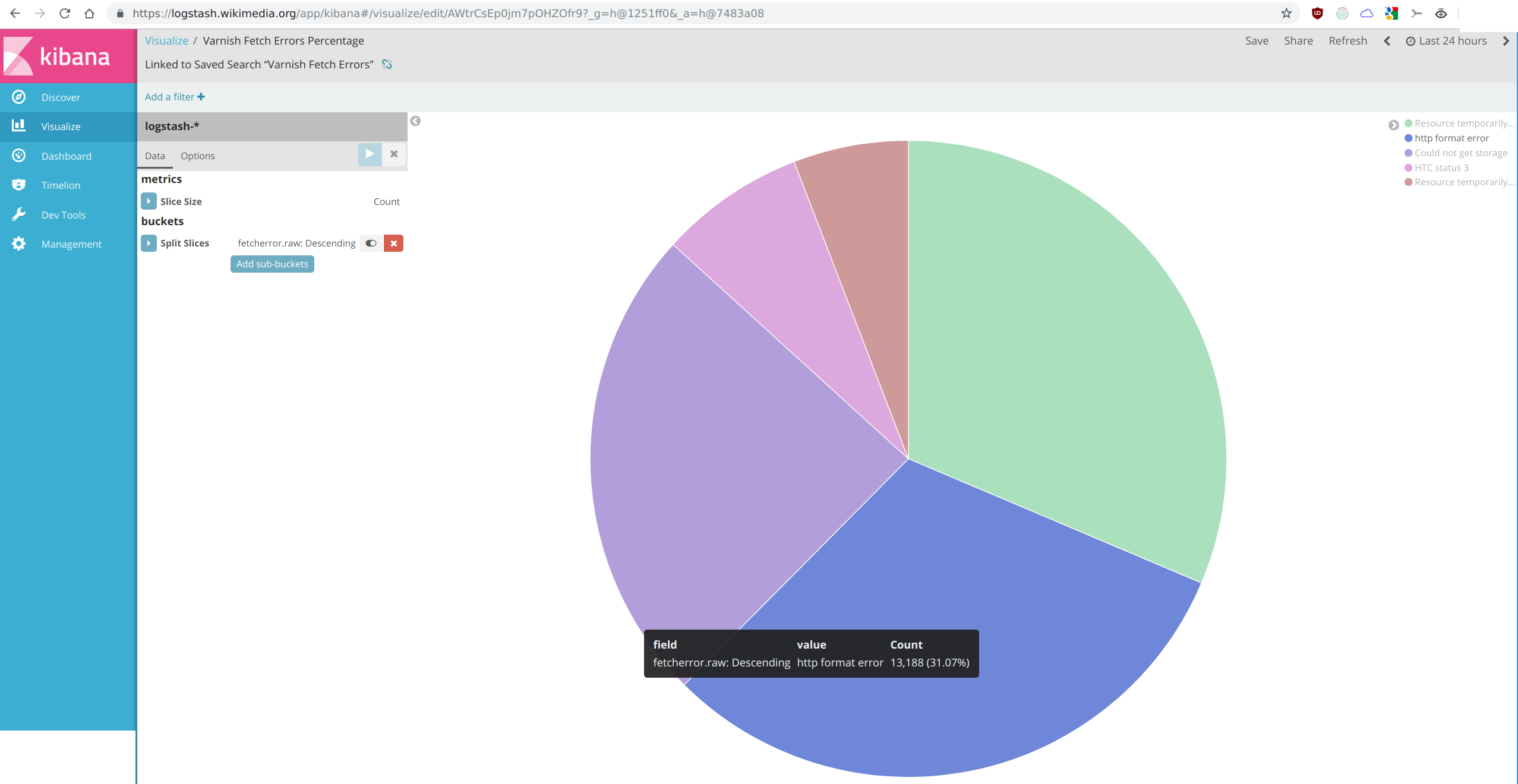
Last 24h at the time of this writing:
| reason | count | percentage |
| Resource temporarily unavailable - straight insufficient bytes | 13279 | 31.4% |
| http format error | 13062 | 30.9% |
| Could not get storage | 10341 | 24.5% |
| HTC status 3 | 3113 | 7.4% |
| chunked read err | 2476 | 5.9% |
"Resource temporarily unavailable" is EAGAIN, and it might be caused by between_bytes_timeout or similar.
$ sudo varnishtest -v bin/varnishtest/tests/b00022.vtc 2>&1 | grep FetchError **** v1 1.5 vsl| 1002 FetchError b Resource temporarily unavailable **** v1 1.5 vsl| 1002 FetchError b eof socket fail
"HTC status 3" is probably due to https://github.com/varnishcache/varnish-cache/issues/1772. Once we patch Varnish and upgrade all hosts to the new version, this error should become "Timed out reusing backend connection".
"http format error" is interesting, it looks like some garbage (sic, that's what varnish calls it) is occasionally returned by the appservers. See https://logstash.wikimedia.org/goto/7338143bb141cf85845385c77b52a944 and https://logstash.wikimedia.org/goto/4bfb870a2c82886a21ababfb898459b5